自定义应用云数据库
当自定义应用需要数据表来存储数据时,就需要在云数据库模块中设计数据库结构。
清林云 BaaS 云数据库 OneDB 作为底层承载所有环境的应用数据,拥有理论上无限的数据存储能力和极快的数据读写速度,保障整个清林云 BaaS 系统的数据稳定和安全。
云数据库模块有两个概念,一个是数据库结构,一个是不同环境下的数据库集群。
自定义应用开发者在设计应用时需要设计好应用的数据库结构,上线后不可变更,不然会和应用使用者环境中的已有数据产生冲突。
清林云用户在安装自定义应用后,就代表将该应用的数据库结构部署到了用户环境的数据库集群中,从而能够储存实际的应用数据。
数据库结构
示例
我们同样拿“简易博客”这个展示应用举例说明。
数据库表的创建如图所示:

首先要填写表ID,也就是数据库集群中的实际表名,尽量为首字母为大写的英文单词,便于识别表的主要代表信息。
其次是最重要的选择表引擎,当你选择引擎后就不可更改了,引擎决定了这个表的功能。如 X2 引擎就意味着该表的数据可以由两个主键同时确定,S1 引擎表示会创建一个搜索引擎,可以进行高级搜索功能。
不同的引擎有不同的功能,详情请查看下方。
然后是写一个表名,就是给这张表设置一个给人看的名字,简单易懂即可,可以是中文。
创建好后,设置表结构如下:
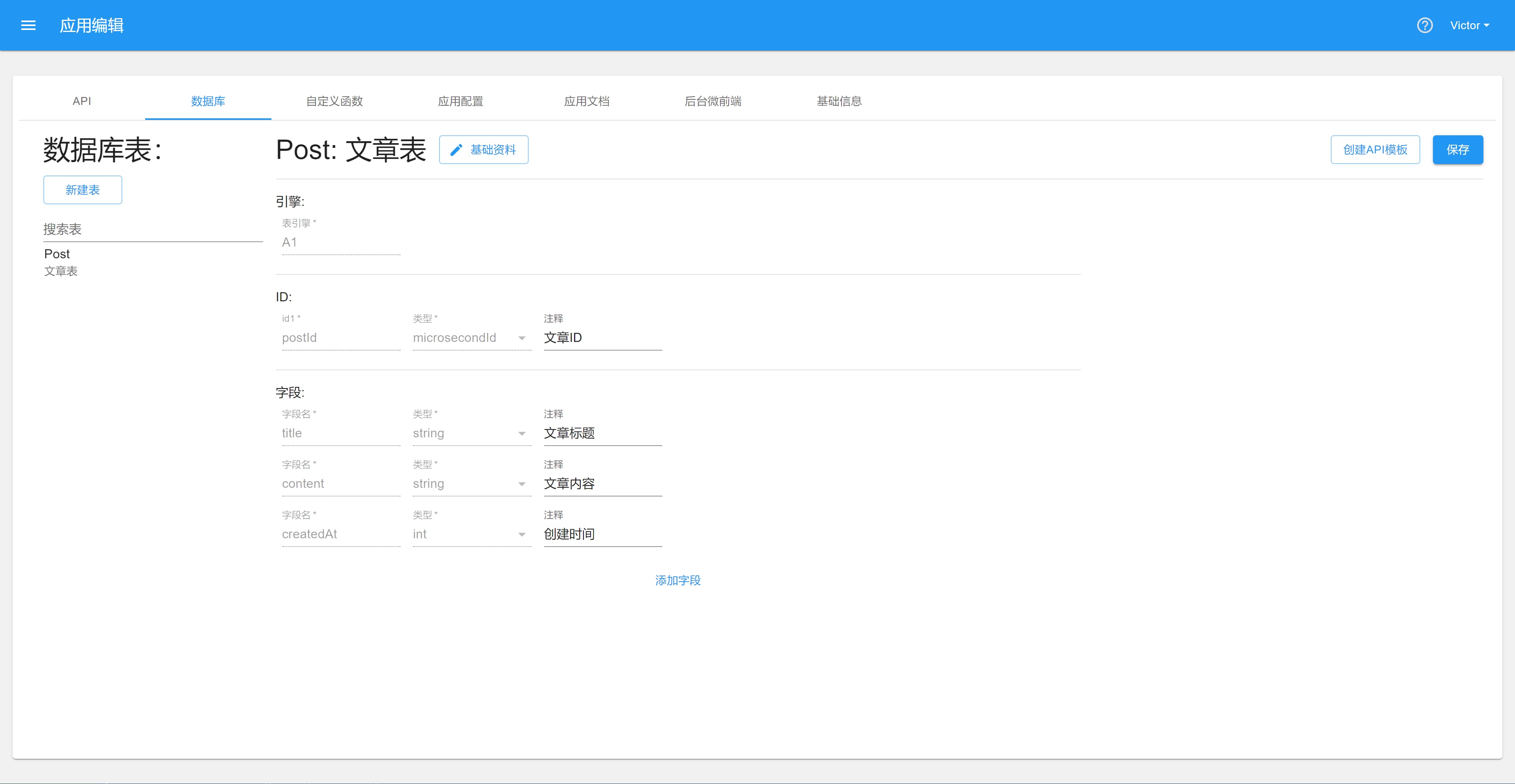
点击基础信息可以修改表名、表注释。
ID 区域都是表的主键,可以设置主键名和注释。主键类型在创建表时已固定,对于数据的查询储存都会使用该主键名。
字段区域是表的列。
字段名和主键名类似,表示该列的名称。
主键名和字段名在设置后不可修改,不然会影响线上用户。
字段类型
主键类型有
string文本:该值的大小上限为 1 KBmicrosecondId唯一微秒
microsecondId比较特殊,只有 A 系列引擎有,即在创建数据时如果指定为唯一微秒,则会生成微秒时间戳,比常规的时间戳还多 3 位。
但是这后三位并不是真实的微秒时间戳,而是一个单点序列器生成的序列,这样就能保证,在任何情况下,这个主键都是唯一的,哪怕在 1 微秒内同时创建两条数据,主键的后三位由于是序列器发号,所以也会不同。
由于此特性,A 系列引擎适用于保证时间序列的数据表,如 IoT 设备数据、消息系统、和需要按时间排序查询的数据。
字段类型有
string文本:该值的大小上限为 1 MBint整数数字float带小数点的数字boolean是或否:即trueorfalse。
另外,S 引擎的string字段最大为 4 KB。
而且 S 系列引擎多了三种类型
text长文本:该值的大小上限为 2 MBnested嵌套类型:最多 200 个自定义数据,大小不超过 1MBgeo地理位置数据
三者本质上都是string字符串,但是区别如下:
test类型在查询时可以进行全文查询,适用于长文本数据的关键词检索。经常用于文章内容检索的场景中。
nested类型可以进行嵌套查询,使用JSON.parse(nestedData)解析后会得到如下结构:
{
"key": "自定义key",
"value": "自定义value"
}
嵌套查询可以指定 key 和 value 的值进行查询。
geo类型可以进行地理位置相关的查询,格式为纬度,经度,纬度在前,经度在后,且纬度范围为[-90,+90],经度范围为[-180,+180]。例如:30.1249,120.9518 。
数据库引擎
清林云的云数据库功能采用 DataMesh 设计架构,由不同的引擎提供不同的功能。
当前数据库引擎有以下几种,更多引擎清林云数据库团队正在开发中,如果你的应用有特殊的结构不适用现有几种,你也可以联系我们加速解决:
引擎的英文首字母为寓意,数字代表了该引擎拥有几个主键。
当前系列:X 键值引擎、A 自增引擎、S 搜索引擎、C 反查引擎、E 生命周期引擎。
所有系列的数据单条插入耗时都在 1-10 毫秒之间,甚至单表亿级数据量也是如此。但 S 系列因为数据要建立索引的关系,插入一条数据后一般需要 0.5 秒后才可以通过 search 动作查询到。
正在专有云、私有云测试,即将上线公有云的系列:O 金融级事务引擎、R 计算引擎、W 流引擎。
X
X 代表极致,简洁和超高的性能,和 Redis 等键值数据库类似,可以根据主键进行数据的点查,但是又可以通过主键组合进行范围查询。
X1
X1 引擎的表拥有一个主键,适用于简单的数据模型。比如说“组织系统”应用中的“组织”Org,它的模型标识就是orgId单主键,可以根据orgId这一个参数查询到该 ID 组织的数据。
单主键也有缺点,就是范围查询getMany只能按照单个主键排序,通常要和其他表配合。
比如说,当用户想要查询他所在的所有组织时,后端只能通过 token 拿到userId,并不知道他所在所有组织的orgId。
那么此时就需要另建一个 X2 引擎的UserOrg表,储存用户User拥有的所有Org数据,通过主键userId和orgId范围查询getMany(确定 userId 设置 orgId 范围为无限大到无限小)该User的所有Org拿到orgId,然后再用该orgId数组并行查询Org数据。
这个方法叫中间表,是所有企业级产品通用的做法,传统数据库的外键方式使用虽然比这样简单,但只适用于小规模数据,现大多数企业禁止使用外键。
X2
在很多情况下,数据关联的场景是最多的,我们不想要这么多中间表怎么办,这时候就需要 X2 引擎了。
比如“组织系统”应用中的“组织分组”OrgGroup,传统的数据库是创建一个Group表,然后再创建一个中间表去把两者关联起来,先查中间表得到所有组织分组 ID,再去根据这个数组单查分组数据。
但是现在我们可以直接使用 X2 引擎创建表,拥有两个主键,第一个主键为orgId,第二个是groupId,这样我们在范围查询getMany时设置第一个主键为固定值即某个组织的 ID,然后groupId的查询值设为无限大到无限小,那么就可以直接查询到该组织的所有分组了。
X2 的使用场景是最多的。
X3
同理可得,X3 拥有三个主键,可以借此拥有三级关系。
比如“用户系统”中的UserRight用户权限,三个主键分别为userId用户 ID、appId应用 ID、target权限目标,即意味着一个用户可以有多个应用的权限,一个用户的某个应用有多个权限目标。
当你在清林云控制台创建一个组织的时候,就产生了一个权限,userId是你的 ID、appId是“组织系统”应用的 IDorg、target目标是你创建的组织orgId假设为xxx,而数据rights是["admin"],即代表你这个用户在组织系统中的xxx组织 ID 下有管理员权限。
你可以创建多个组织,有多个组织的权限,也可以在其中一个组织里拥有多个权限目标比如某些分组 ID 和功能标识,在这些权限目标下有各种各样的实际权限。
你也可以在其他应用中拥有其他应用的多个权限。
没办法,三级关系就是如此复杂,但同时在某些场景下功能极其强大。(该例子中的rights可以被解析为数组类型,相当于四级关系,某个用户在多个应用的多个目标中可以有多个权限类型)
A
同 X 系列,A1、A2、A3 即有不同主键数量的表,唯一的区别就是最后一个主键是唯一微秒类型。
引用前面讲的数据类型内容:
microsecondId比较特殊,只有 A 系列引擎有,即在创建数据时如果指定为唯一微秒,则会生成微秒时间戳,比常规的时间戳还多 3 位。
但是这后三位并不是真实的微秒时间戳,而是一个单点序列器生成的序列,这样就能保证,在任何情况下,这个主键都是唯一的,哪怕在 1 微秒内同时创建两条数据,主键的后三位由于是序列器发号,所以也会不同。
由于此特性,A 系列引擎适用于保证时间序列的数据表,如 IoT 设备数据、消息系统、和需要按时间排序查询的数据。
需要注意一点,在 update 数据或 delete 数据时,A 系列的默认条件是期待存在,即更新和删除需要传入的微秒值必须对应已存在的数据。
E
同 X 系列,E1、E2 也是有不同主键数量的表,但是区别在于 E 系列表拥有生命周期,存在该表中的数据在 24 小时候会自动删除,适用于一些临时数据或限时数据。
如“组织系统”的邀请链接InviteLink就会在创建后的 24 小时候自动删除从而造成链接失效以防安全。
使用该表就可以不再维护一些长时间轮询的任务,在某些场景下效益非常大。
C
在很多应用的场景会有这样一种情况,就是,我不仅想要通过UserOrg查询用户User拥有的所有Org数据,还想要通过Org查询所有组织拥有的成员User,也就是刚好反过来了。
此时一般的解决方法是再创建一个OrgUser表去关联,但是这样就会造成业务逻辑太麻烦。这时候 C 系列引擎就出场了。
C1、C2、C3 和 X 系列相同,也是分别有 1、2、3 个主键,但是 C 系列额外拥有系统级的镜像表。
C2
在上面的场景中,我们将UserOrg设置为 C2 引擎,主表的主键为userId和orgId,和 X2 的作用相同,能够范围查询(确定 userId 设置 orgId 范围为无限大到无限小)该User的所有Org的中间表数据。
但是在步骤设计中,我们选择 C 系列时会出现额外选择框镜像表,默认是正表,效果和 X2 相同,但是当选择镜像表时,则相当于使用了主键为orgId和userId的表,主键次序刚好反过来,能够通过确定orgId并设置userId范围为无限大无限小进行getMany范围查询到该组织的所有用户。
即 C2 的主键为id1 id2时,它的镜像表主键为id2 id1。
C1
那么 C1 没有两个主键怎么反转次序呢?所以 C1 的镜像表并不是反转主键,而是将一个列提升为第一主键,原主键成为第二主键,形成了一个 X2 引擎的表。在创建 C1 引擎表时,会看到自动生成了一个字段cid,使用正表是和 X1 相同,但是使用镜像表时,就变成了cid和原主键结合的 X2 类型的表。
举个例子,一个文章系统有Post表,我们经常通过https://xxx.com/post?postId=aaa这种链接直接打开文章页面,服务器此时只能得到postId这个值,虽然Post实际上属于User,但是因为查询 X2 需要同时两个主键,而网站不能直接得到文章的userId,所以我们不能将Post设置为 X2 引擎。
此处我们将Post设置为C2引擎,cid 实际设置为userId的值,那么我们即可以通过单个主键单查,也可以通过镜像表使用cid和无限大无限小的postId来范围查询某用户的所有文章。
虽然你也可以通过建一个中间表来关联两者关系来实现此功能,但是 C1 更为方便,而且重要的一点区别是,你可以更新 C1 引擎的数据,从而自动更新镜像表关系。也就是说,update 文章的cid可以直接将某用户的文章移到另一个用户名下,当然这个例子不符合正常的逻辑,但是在某一些场景下会有更大的方便性。
即 C1 的主键为id1时,它的镜像表主键为cid id1。
C3
那么 C3 有三个主键,是怎样的次序去反转镜像呢?
C3 非常特殊,因为它会有两个镜像表。例如我们的主表主键为:id1 id2 id3,那么第一镜像表的主键顺序就是 1 开头 id1 id3 id2,第二镜像表的顺序是 2 开头 id2 id3 id1。
这个就比较复杂了,适用于特殊场景。比如说“组织系统”的GroupMember分组成员表:
GroupMember表的主键为orgId groupId userId,即组织拥有多个分组,分组又拥有多个分组成员,是典型的 X3 系列的三级关系。但是此时又有需求,我希望用户能查询用户在该组织的所有分组,也能查询用户加入的所有组织。这时候 C3 就恰好合适。
我们通过 C3 的第一镜像表即主键为orgId userId groupId,可以轻松查到用户在该组织内所有加入的分组。
而第二镜像表主键是groupId userId orgId要怎么查用户的组织呢?此处我们巧妙地设置了一个分组 IDroot,即用户加入组织时会自动加入一个groupId为root的分组,代表了全体成员组。这时候在范围查询getMany时,设置groupId为固定值root,userId为用户 ID,orgId范围无限大无限小,那么就可以查到该用户的所有 root 组,相当于用户的所有加入组织。
可以看到,通过一个简单的 C3 引擎,我们上面在 X1 和 C2 引擎中的举例UserOrg就直接被替代了。一个表实现三种功能,非常强大,但必须注意顺序是否符合应用的场景。
C 系列注意事项
C 系列的主表和 X 系列相同,但是镜像表有限制,即只能镜像储存 10 个string类型的列,5 个int类型的列,3 个float类型的列和 2 个boolean类型的列,根据先来后到原则,所以设计时 C 系列表,尽量把镜像表需要的数据列排在前面。
毕竟镜像相当于复制一份主表数据,对系统有一定压力,全量复制的实际场景并不多,所以够用就行。
如果某些场景比较特殊,20 个列依然无法满足,那么也可以根据镜像表的数据数组再并行get一下相关数据表就行。
在这里,镜像表不仅仅是方便,镜像的意思还有性能,传统数据库维护相反关系的两张中间表同步时需要一定延迟,但 C 系列几乎没有延迟,更新主表后同时查询镜像表也是得到最新数据。
S
S 系列引擎和 X 系列基本相同,只不过当用户使用 S 系列的表时,该环境会在 X 系列的基础上创建一个类似 Apache Solr 的搜索引擎,通过在search动作下添加多个搜索条件可以实现多种类型的查询。
使用 S 系列引擎的表通常 API 成本会在原来基础上+1 。
S 系列的主表和 X 系列相同,搜索表使用限制有:
- 最多索引 40 个
string类型的列; - 最多索引 20 个
int类型的列; - 最多索引 20 个
float类型的列; - 最多索引 20 个
boolean类型的列; - 最多索引 5 个
text类型的列; - 最多索引 5 个
nested类型的列; - 最多索引 10 个
geo类型的列;
所以在设计 S 系列表时尽量将重要的数据放前面,这样直接search就可以查到必要数据而不用再次get反查主表。
不同搜索条件的功能详情和翻页排序等特殊功能可以查看API 步骤章节。
更多
清林云团队将继续开发更多的云数据库引擎以适应更多场景,如果你的应用有以上系列无法满足的场景,请与我们联系,我们将根据用户需求更改实现优先级。