Feed 流系统
Feed 流就是信息流,市面上主流的有三种。
第一种是最简单的,由平台自己或职业人员产生内容,用户可以按时间顺序查看到统一类内容的信息流。常见于官网内容、专业媒体或精选内容等产品。比如知乎日报、虎嗅等,该类产品可以使用 CMS 系统实现。
第二种是推荐类,也就是由推荐引擎将用户感兴趣的内容推荐给用户浏览,典型的就是今日头条、抖音等。该类产品需要标签系统,智能内容系统,计算引擎,推荐引擎等配合,清林云未来不久将会推出该类应用。
第三种就是订阅类信息流,也就是根据用户的关注、订阅、好友关系等,浏览相关内容,最有代表的就是微博,朋友圈,B 站这些。我们将在下面实现一个该类型的自定义应用。
我们用一个基础的 Feed 系统来展示清林云自定义应用能力。基础版本能满足大部分基础需求,但是每家组织的 Feed 流系统需求都不相同,所以你也可以在这个基础上再自行添加更多高级的个性化功能。
需求
我们需要一个订阅类 Feed 流系统,可以实现基于关注关系的内容订阅。
所以该系统需要有一个订阅关系,能够关注其他用户,当被关注的用户发布动态后,关注的用户就可以在自己的信息流中查看到该动态内容。
基本上这是一个社交、信息类产品的必备功能。基于该 Feed 流,可以实现类似微博、朋友圈的功能,提高用户使用度。
功能分析
在技术上,订阅类 Feed 流系统还分为三类:
一、推模型(多写)
也就是当一个用户发布动态后,后端将先查询所有关注他的用户,然后将该动态的数据插入到所有关注用户的信息流中。
比如说,当你有 2000 个微信好友时,每当你发一条朋友圈,微信后端将会先查询你的所有好友,然后分别给这 2000 人的朋友圈动态中插入你发布的内容。
该模型的优势是逻辑简单,用户刷新朋友圈内容时性能好,占用查询资源小。
但缺点是发布时不好瞬间写入太多数据,比如当你有 100 万个好友时,那么发一条朋友圈将会在后端瞬间写 100 万条数据,这就给后端的压力太大,很难实现。这也是为什么微信只允许有 5000 个好友能查看朋友圈的原因之一。
二、拉模型(多读)
上面的情况当然不能适用于微博、B 站这种账号有大量粉丝的产品,所以就会使用拉模型。
就是当用户打开产品时,将会先查询用户的关注列表,然后根据上次查询数据的时间,查询所有关注了的用户新发布的内容,然后将这些内容存到自己的信息流中再去浏览。
所以使用该模型时,比如有一个大 V 有 1000 万粉丝,当他发布一条动态时,仅仅是一个简单的新增一条数据。而当其他用户打开产品或者是刷新动态时,才会查询到该内容并写入自己的信息流中,同时在线并刷新的粉丝当然不会太多,所以就实现了大量粉丝情况下的 Feed 流。
该模型的缺点就是略微复杂,然后用户查询的资源消耗多,这也就是为什么 B 站限制最多只能关注 2000 人的原因之一。
三、推拉结合模型(读写结合)
上面两种方法都有优点和缺点,所以就又出现了推拉结合模型。
当一个用户的粉丝量小于 5000(假设值)时,发布内容时将使用推模型,超过时使用拉模型。
浏览用户打开产品后,查询关注列表中的大 V,读取他们的最新内容存入自己的信息流,而那些小 V 的内容则早就在发布时已经存在自己的信息流中了。
该模型唯一缺点就是实现起来较为复杂。
本应用
清林云以前实现过很多类似系统,所以就直接简化了很多复杂的部分,然后这里我们将实现一个非常简洁的可推可拉可推拉结合模型的 Feed 流。
动态项 FeedItem 的 ID 我们将使用时间戳随机值,也就保证了数据都是按时间排序,这样好查询,插入用户信息流时也比较容易,保证是唯一的。
然后推模型使用pushFeed API,拉模型使用pullFeed API,你可以在使用该应用时自行判断用哪一个,也可以结合使用。
比如说,当你的产品用户关系较小,使用推模型,那么当用户发布内容即createFeedItem时则同时调用pushFeed将该动态同步给所有粉丝或好友。
当你的产品用户关系为大 V 型,那么使用拉模型,每当用户打开或刷新时就调用pullFeed API 把最新内容存入自己的 Feed 中,然后使用getManyFeed查看即可。
当你想要两者结合时,那么就在发布内容时判断一下是否小 V 去推,并且在pullFeed时调用参数中加入isStar为true。
数据库结构
Feed 动态
Feed 是“我的动态”,即不管是推模型还是拉模型,最终所有关注的人发的动态都会归于此处,这样有更好的查询性能。
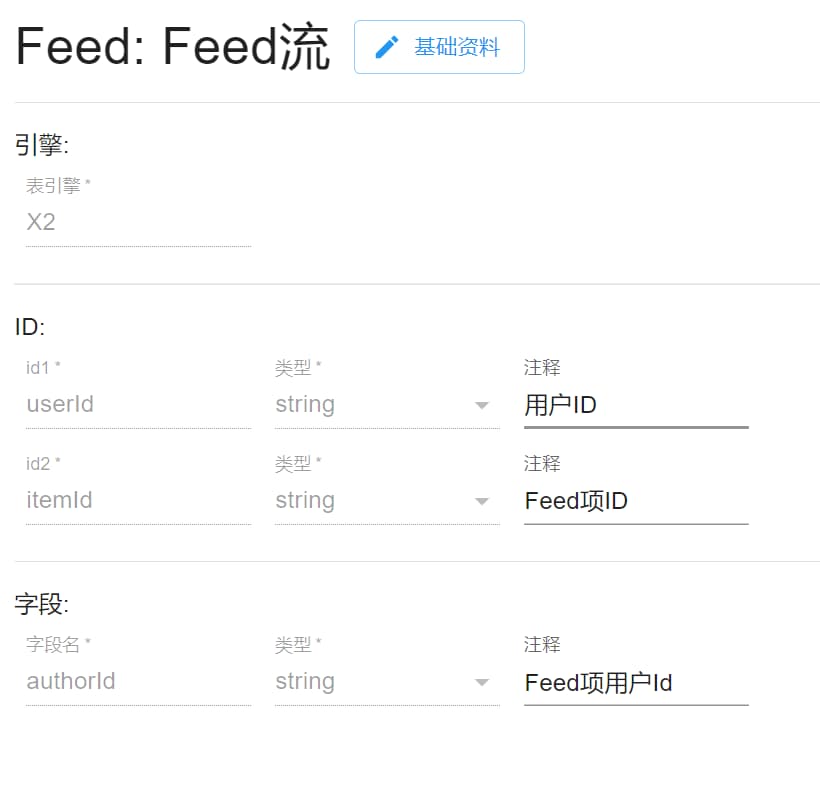
FeedItem 动态项
动态项就是具体的动态,简单的动态数据可以通过 content data 这两个字段来实现内容,复杂的也可以通过 contentId 链接额外的应用查看相关数据。
这里 feedId 的值将在 API 中采用时间戳随机值,在保证了 Feed 流都是按时间排序时也保证了严格的唯一性。

Follow 关注者
当我们关注某用户后,需要该表来记录我们的所有关注数据,另外被关注的用户也可以查询谁在关注他,所以这里我们使用 C2 引擎。

UserData 动态数据
最后一个用户的 Feed 系统数据表来记录一些数值,这样就在查询某些常用的数值时不需要去查询所有相关数据再计算,这样有更好的性能,也更方便。

API
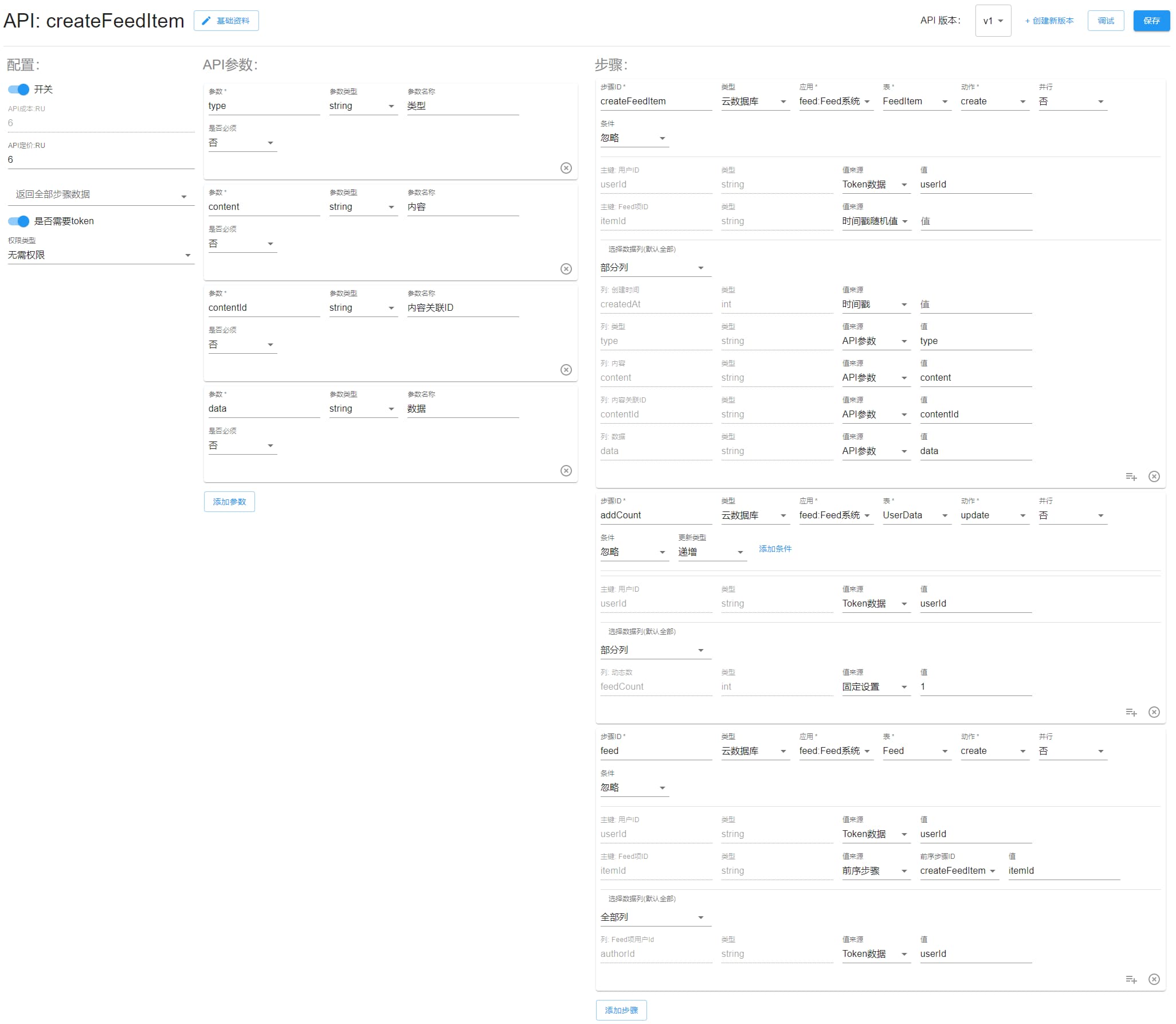
createFeedItem
创建 Feed 项,同时也会在自己的 Feed 中插入一条进去,并更新动态数。
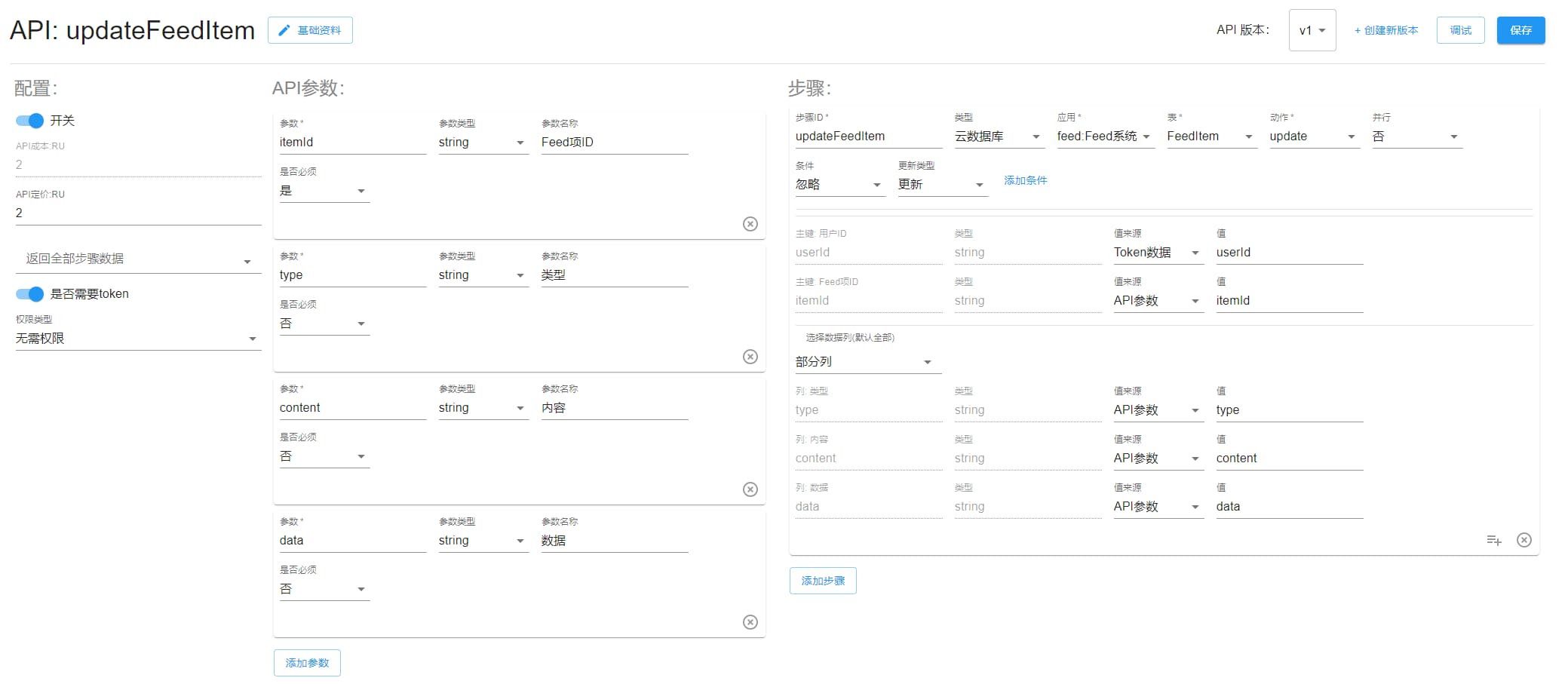
updateFeedItem
更新该内容。
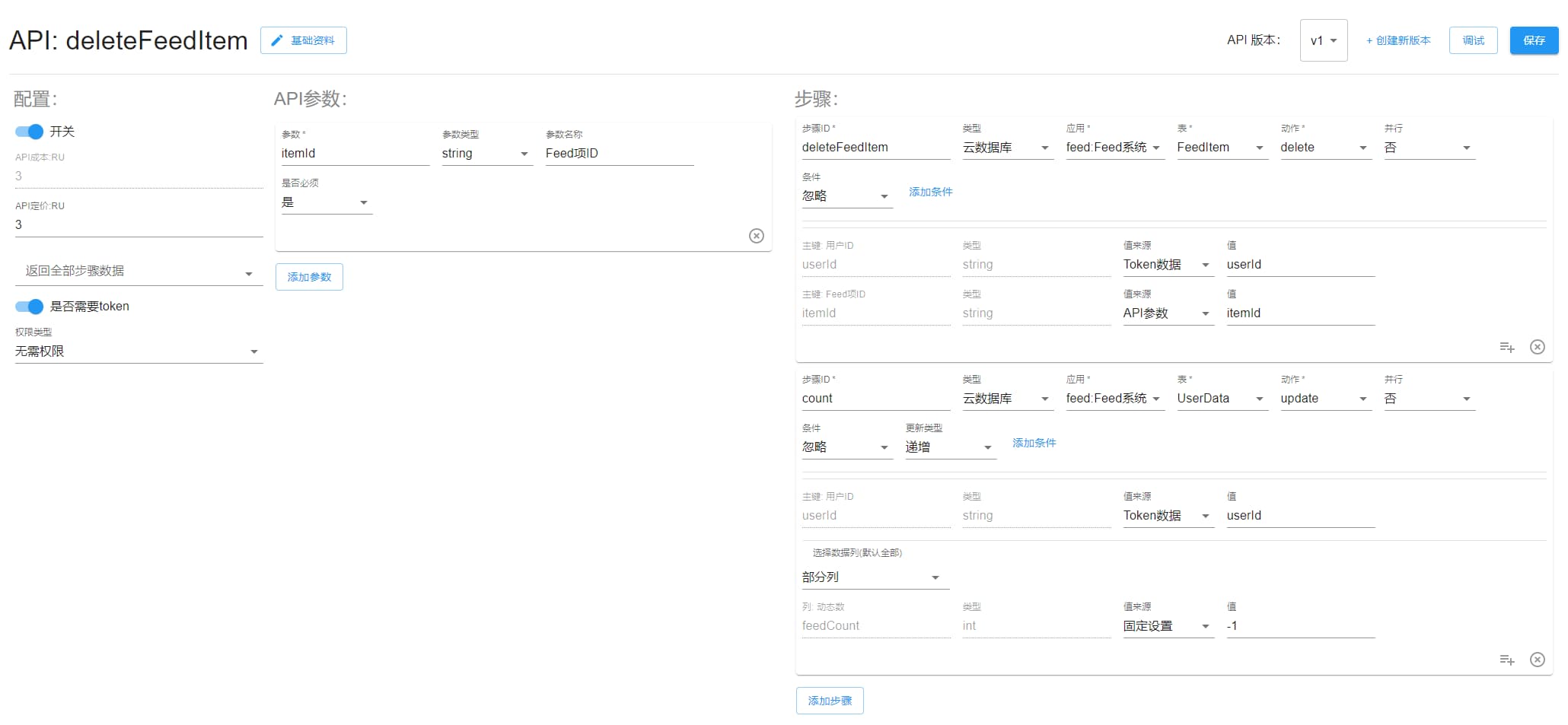
deleteFeedItem
删除 Feed 项,更新动态数。
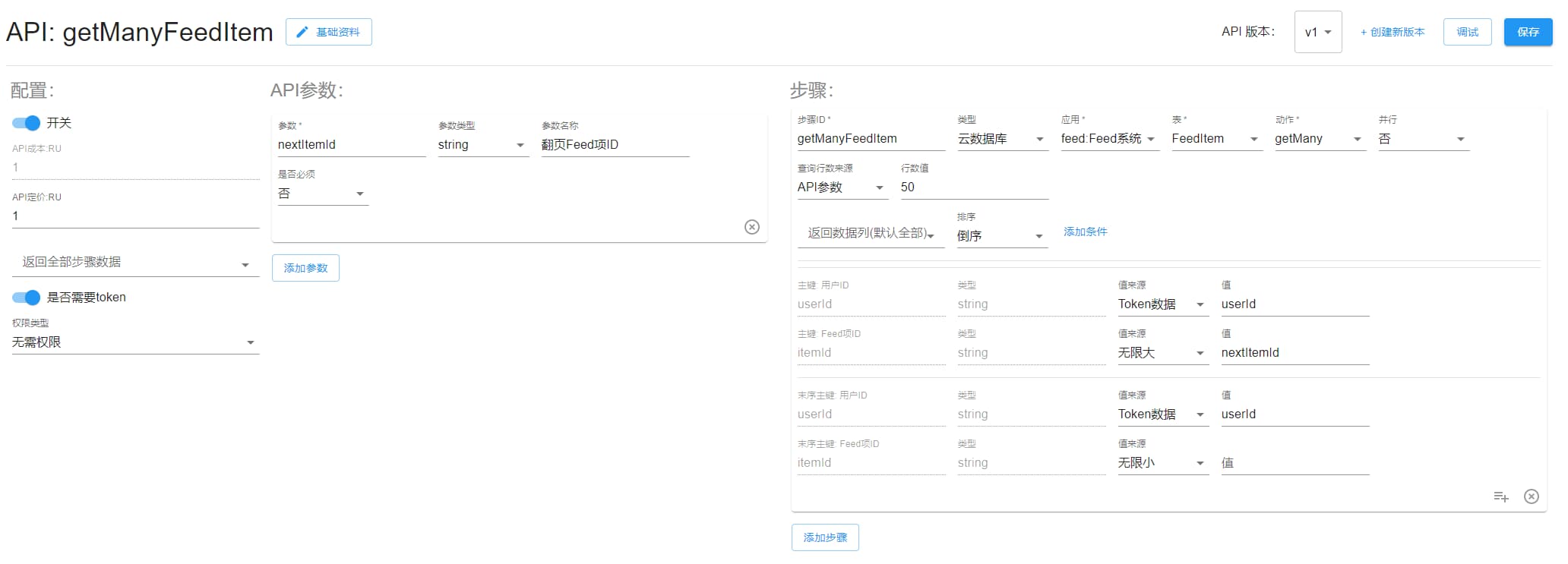
getManyFeedItem
查询“我”发布的动态
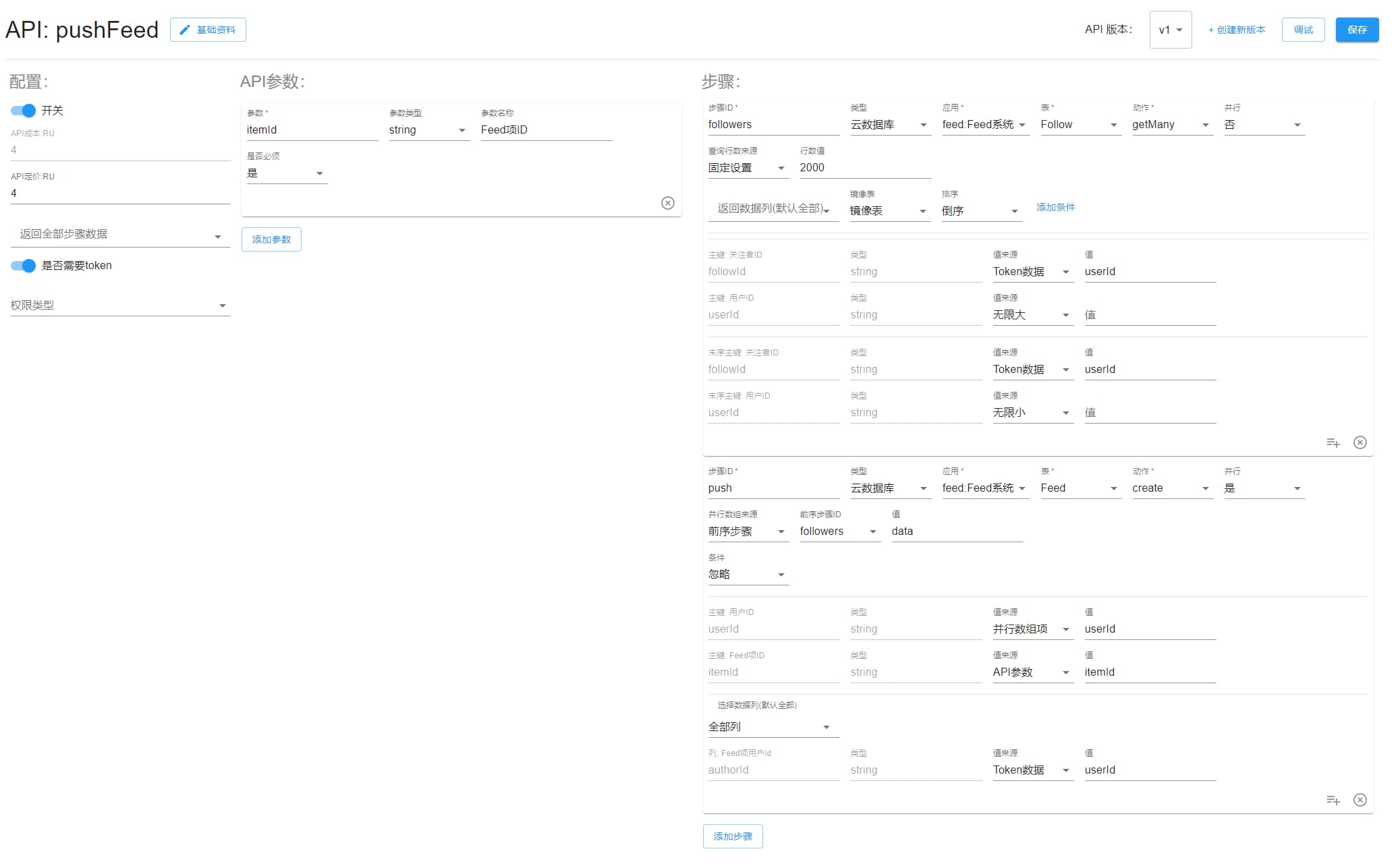
pushFeed
推模型,将会把该项写入到最多前 2000 个粉丝的 Feed 流中。
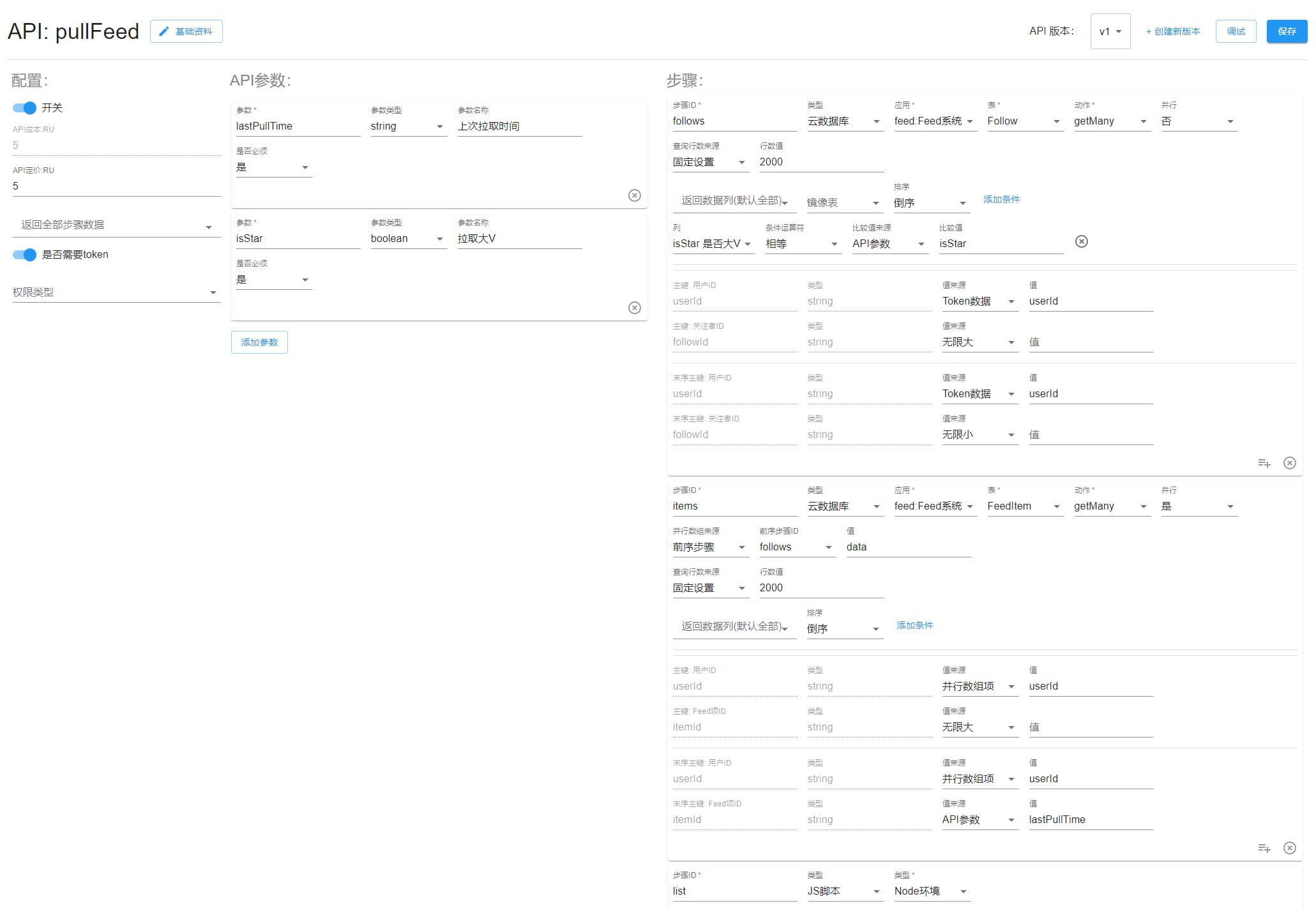
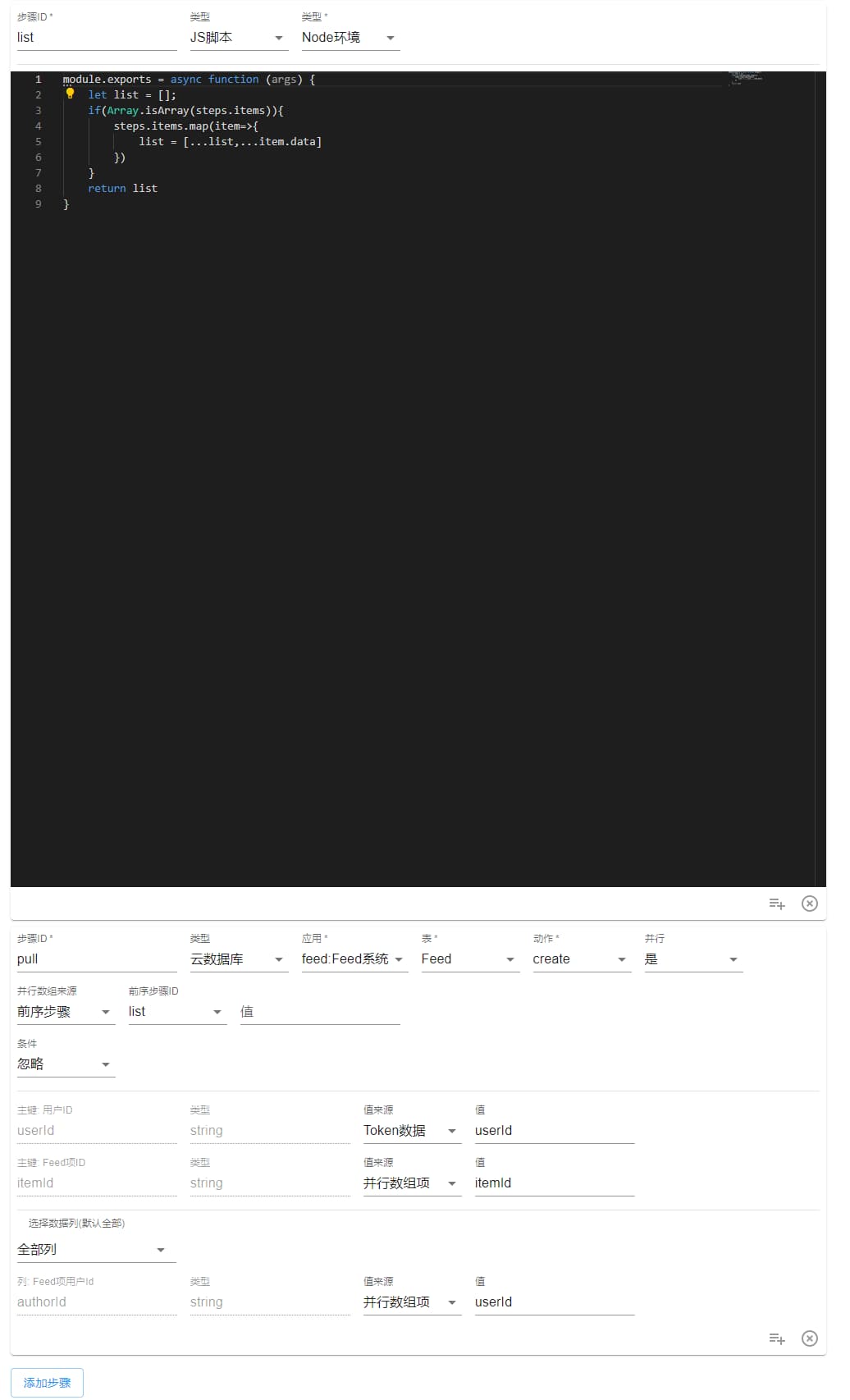
pullFeed
拉模型,将会查询最多前 2000 个关注的用户,然后将lastPullTime之后的新内容写入自己的 Feed 流中。
注意这里可以控制是否拉大 V,当你仅仅使用拉模型时,关注关系那边新建的时候就统一为false,这里同样传入false即可。当你使用推拉结合时,这里调用参数传入true,则只会查到关注时为大 V 的用户。
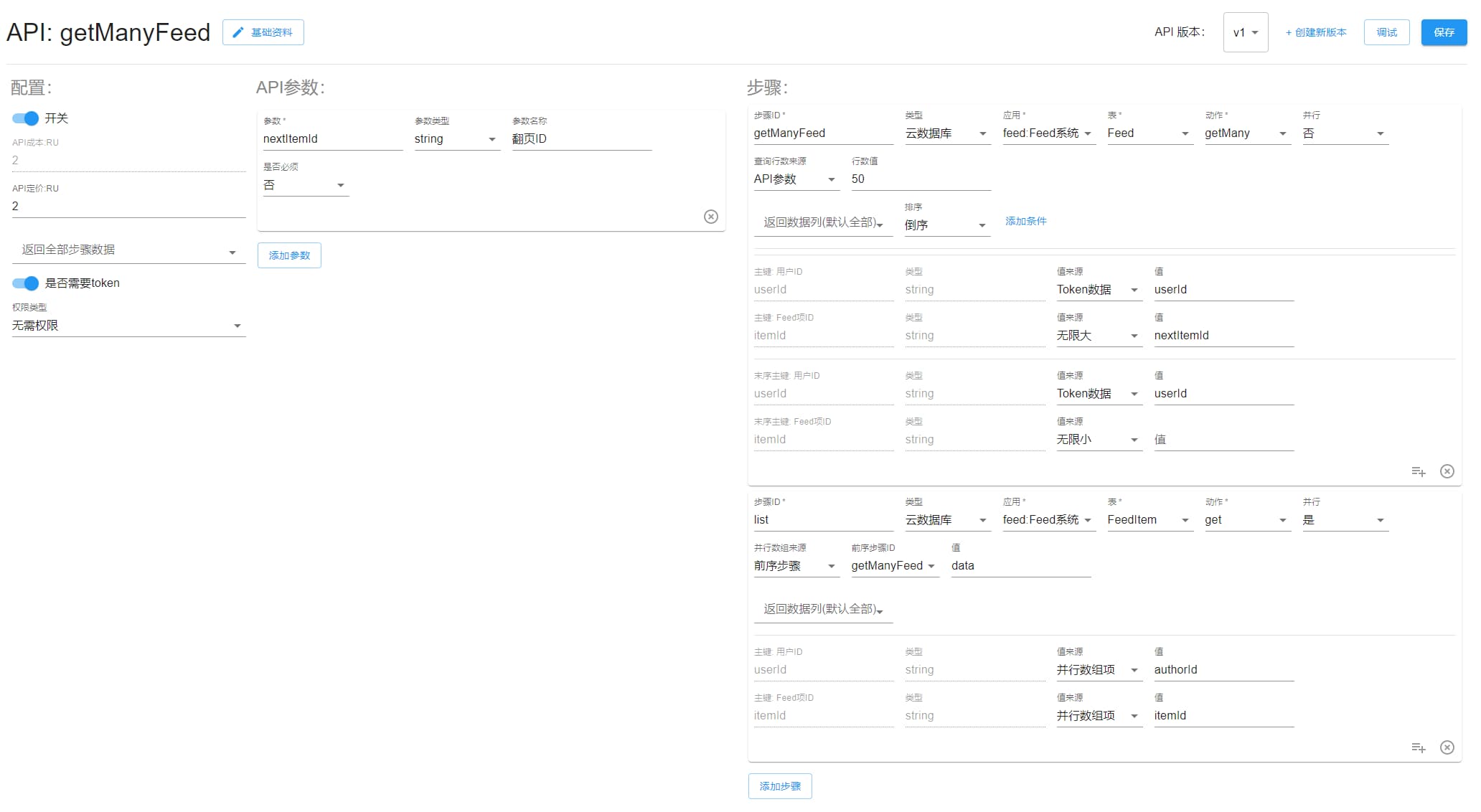
getManyFeed
查询信息流。
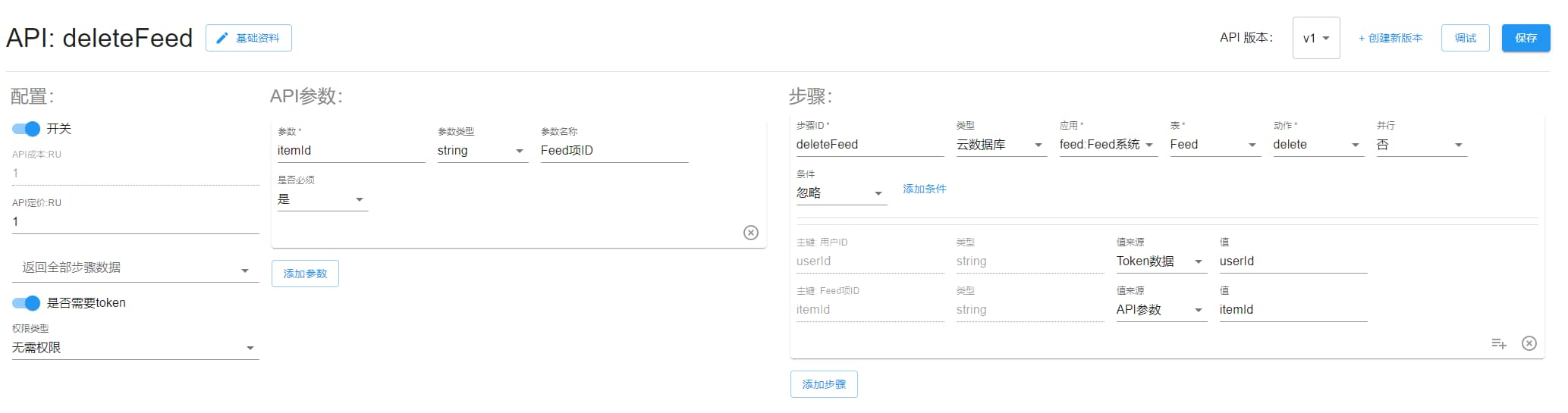
deleteFeed
从信息流中移除某动态。
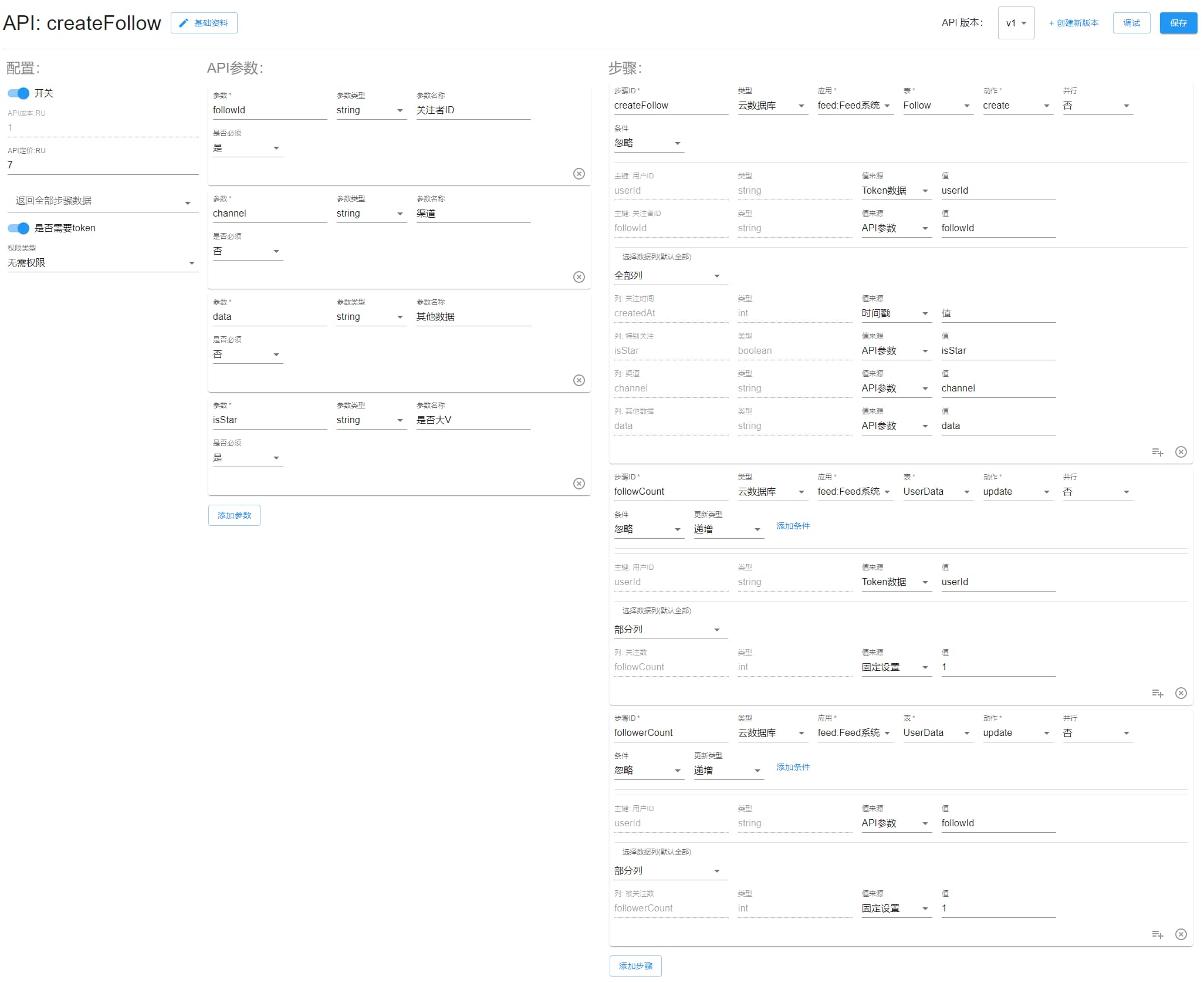
createFollow
新增关注。
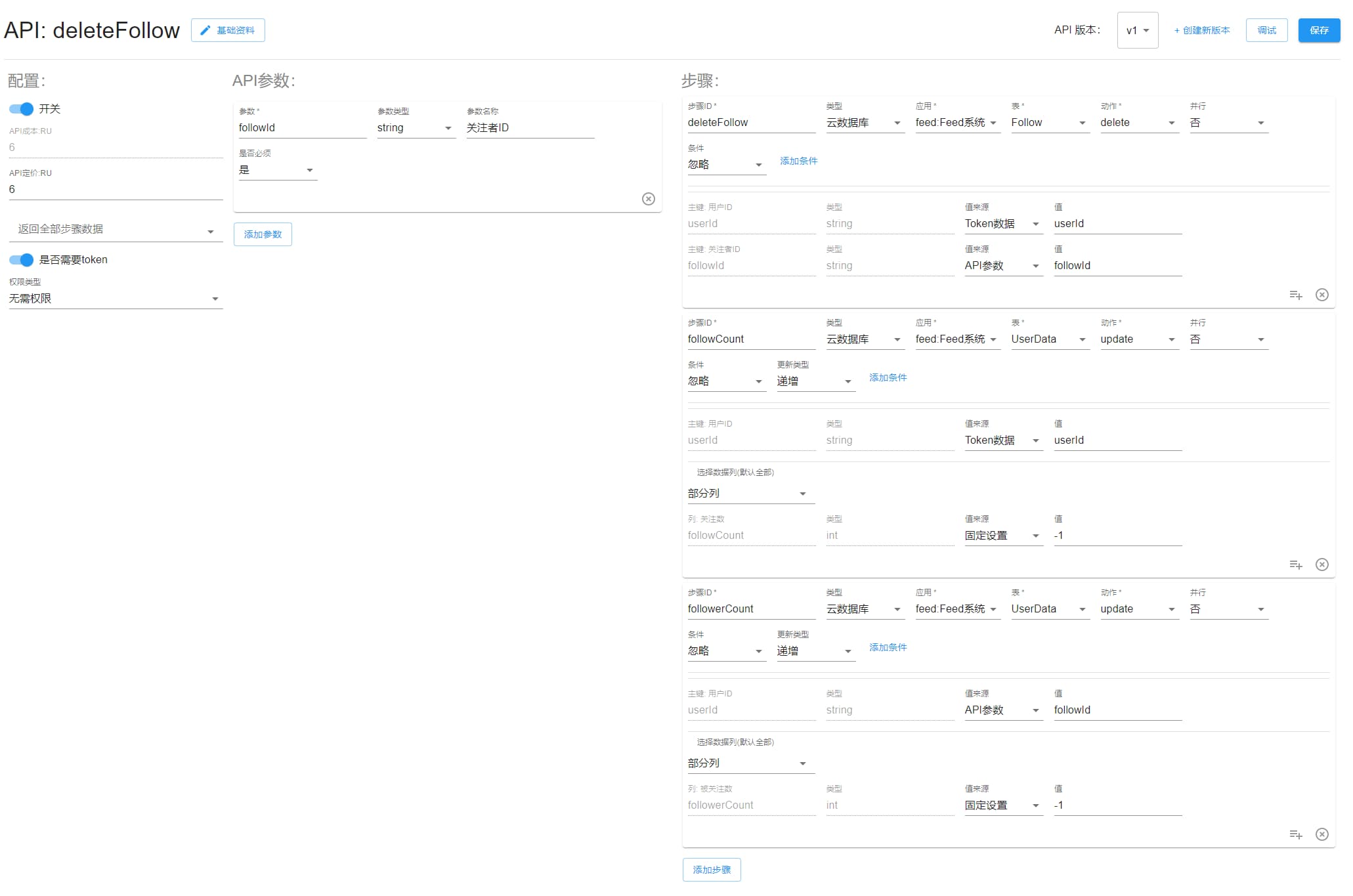
deleteFollow
取消关注。
deleteFollower
移除粉丝。
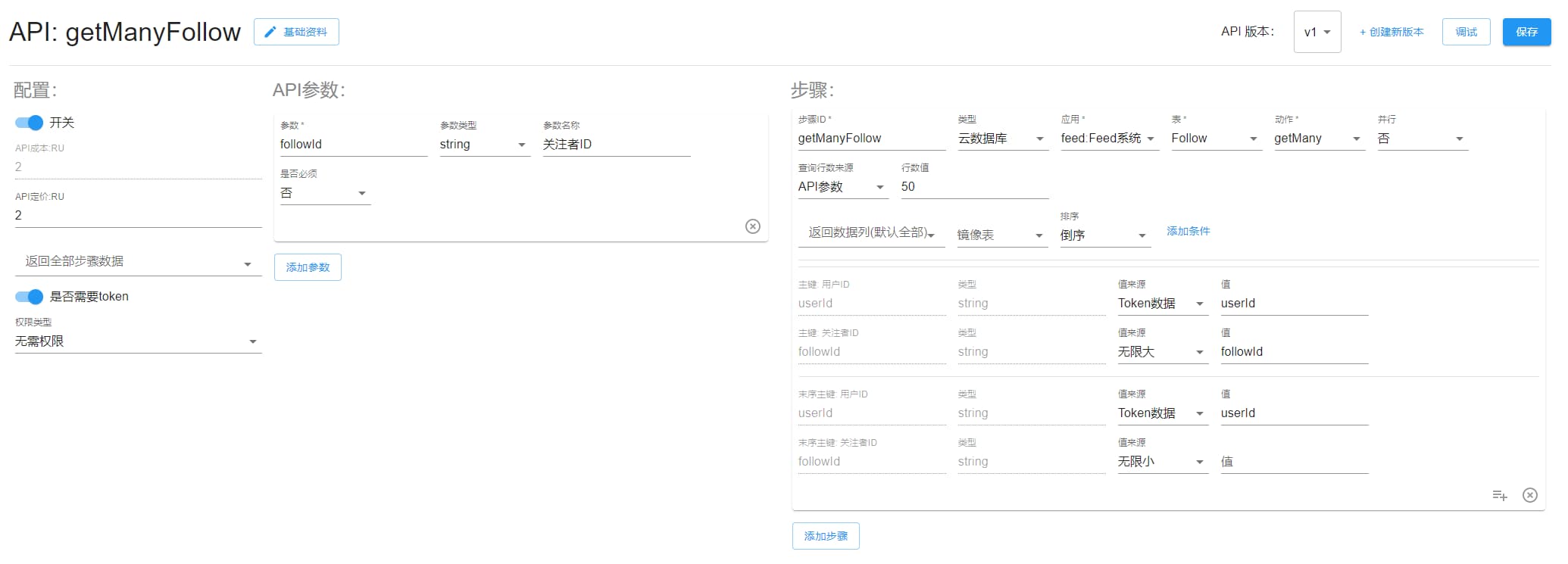
getManyFollow
我的关注。
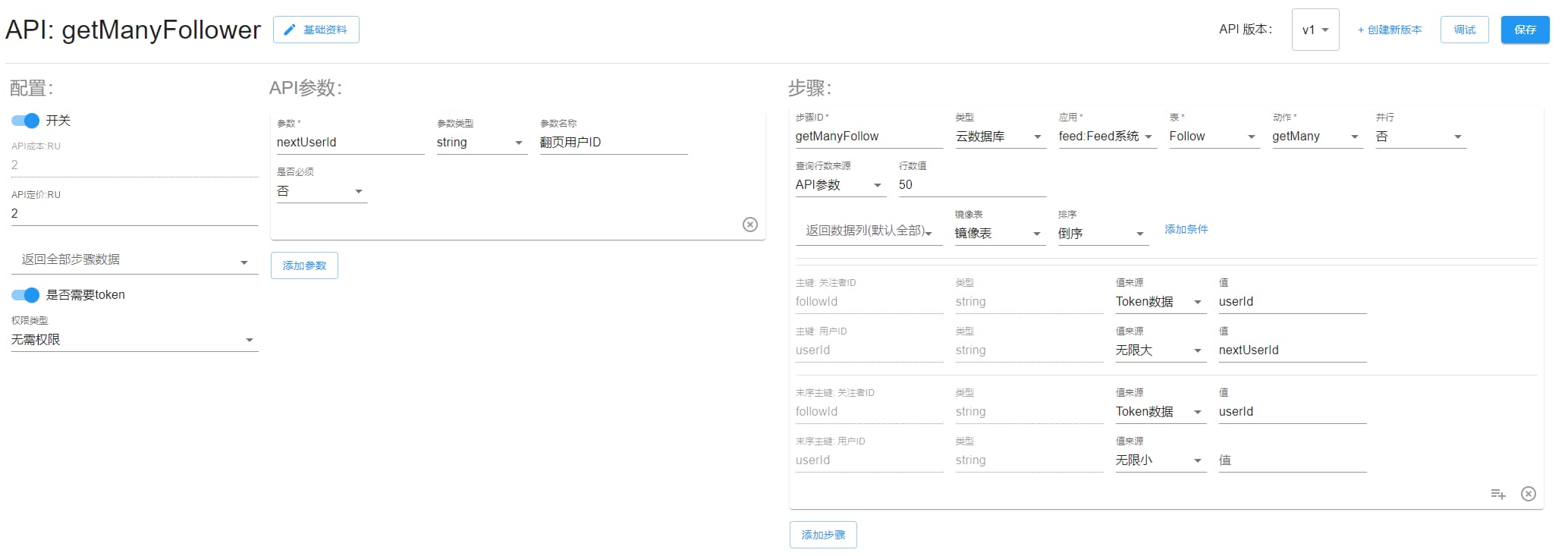
getManyFollower
关注我的。
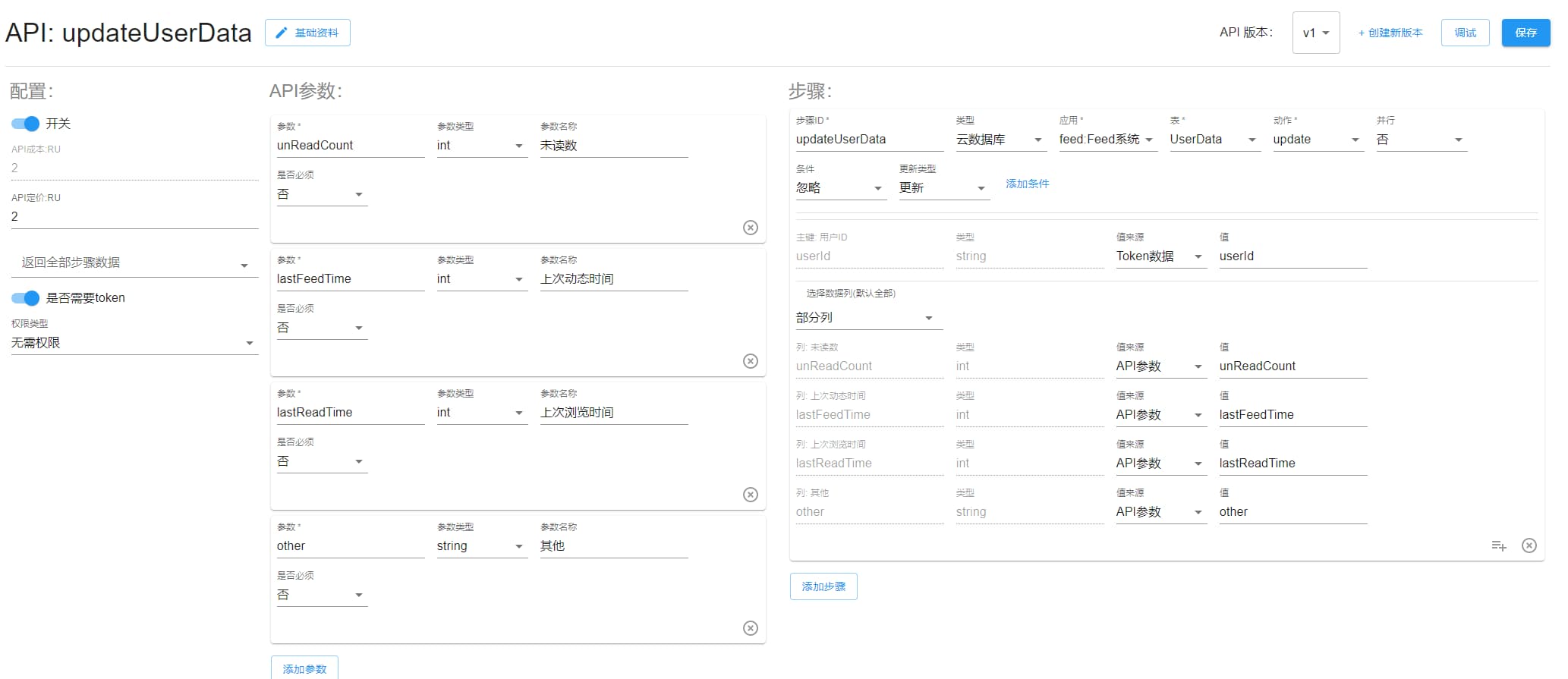
updateUserData
更新用户 Feed 数据。
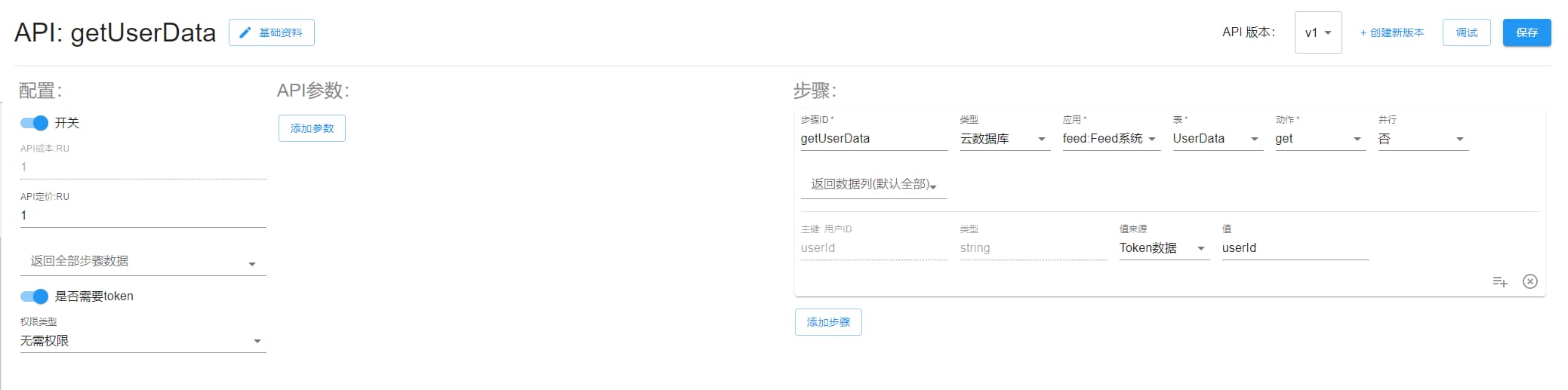
getUserData
查询用户 Feed 数据。
界面
该应用暂无开源项目示例,后续将更新开源一个实际使用中的项目代码,敬请期待。