自定义应用 API 步骤类型详细说明
在上一节,我们初步了解了 API 步骤区域的功能,本章我们来逐个详解所有步骤类型,在了解所有类型后,相信你可以通过组合所有不同的步骤,来开发出各种各样的应用,提供给用户完善的产品功能。
通用部分
如图所示:
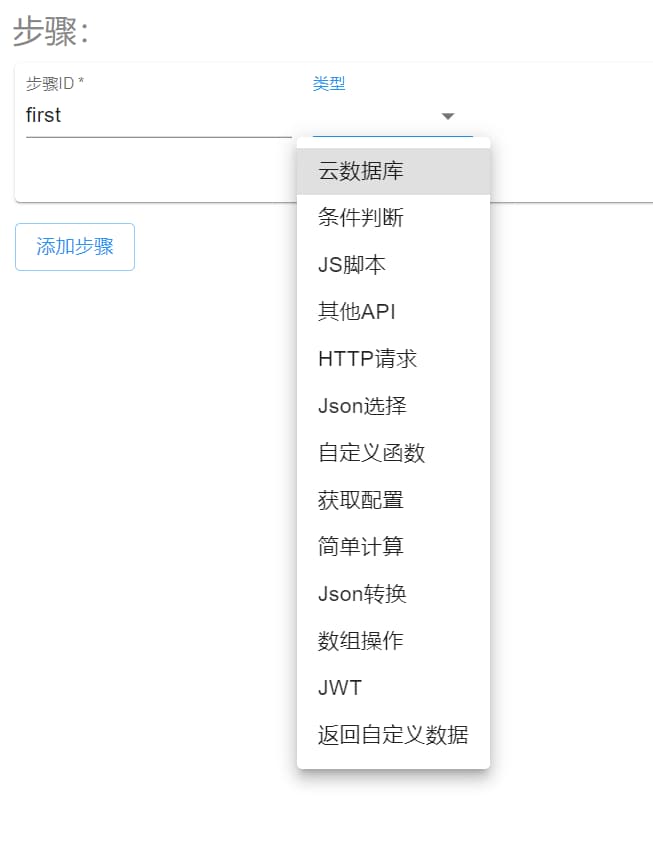
点击 添加步骤 可以增加一个步骤卡片,步骤卡片的右下角有两个按钮,左侧为 在该步骤前添加一个新步骤,右侧为 删除该步骤。
在编辑之前首先输入 步骤ID 以便区分不同步骤,再选择不同的步骤类型。
此处的 步骤ID 将在后续使用,用于步骤之间的某些 值来源 互相引用。
值来源详解
在步骤中,我们需要设置一些实际处理的值,这些值肯定不能全部写死在控制台界面,它是活的数据,所以会由 值来源 这个选项和 值 去确定实际的数据来自哪里。
我们以 create 动作为例,值来源有这些:
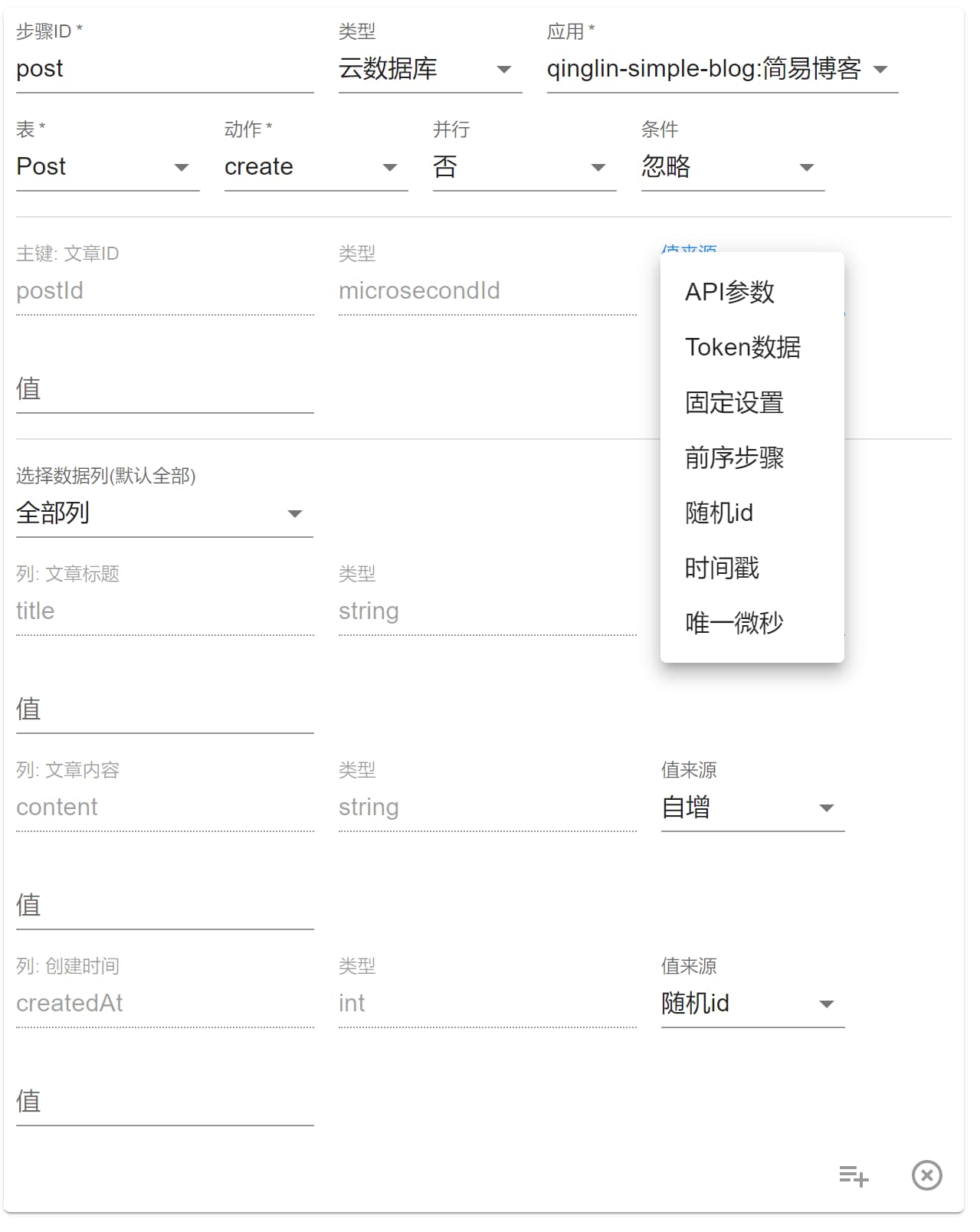
将 值来源 选为 API参数 并设置 值 为 postId 时,就表示会用请求参数的 postId 数据去查询文章。模拟请求如下:
{
"body": {
"appId": "example",
"api": "test",
"version": "latest",
"args": {
"postId": 001
}
}
}
该步骤实际执行中就会查询一篇 ID 是 001 的文章。
前序步骤 能够引用前面步骤的返回数据:
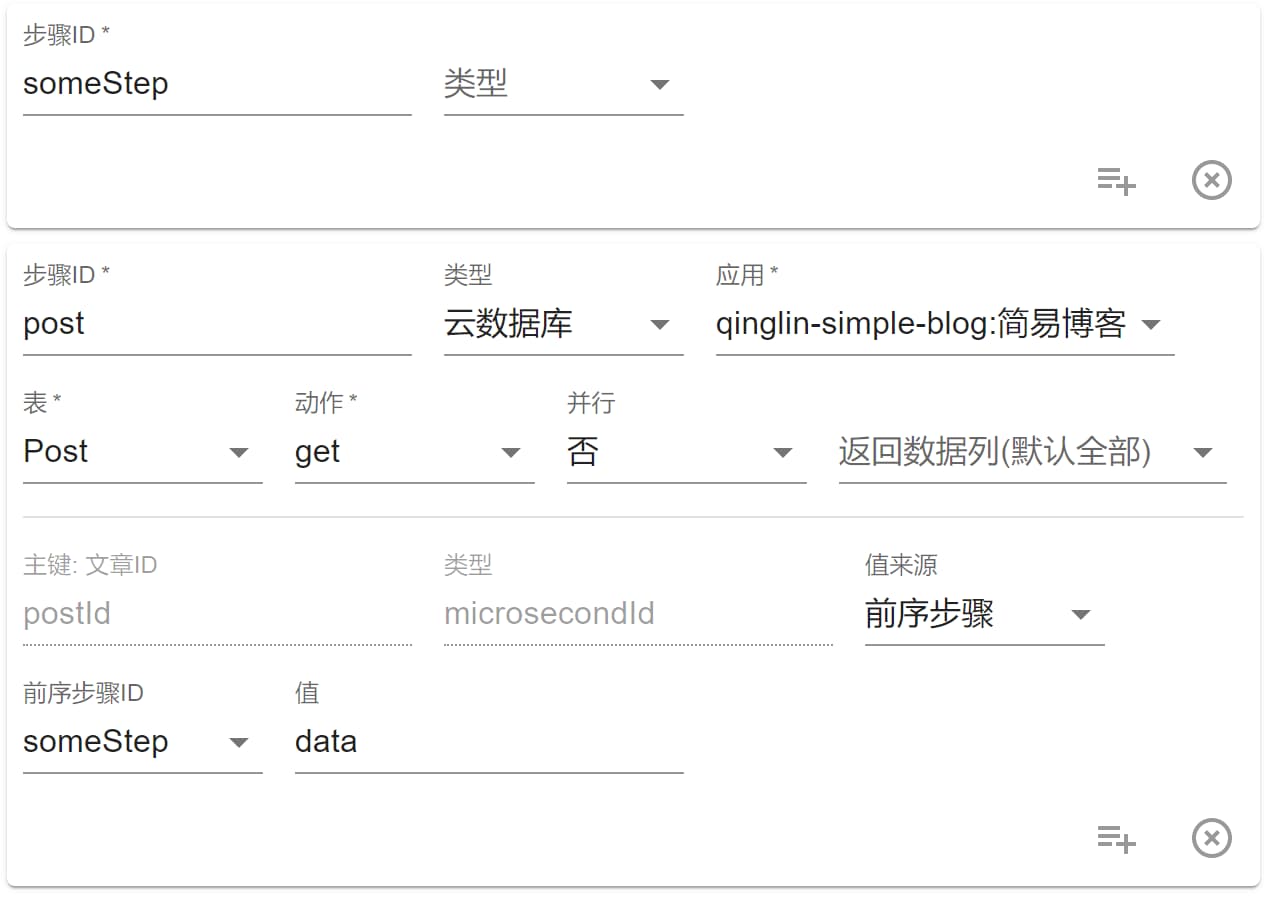
如此处,引用了前面的 someStep 步骤的 data 值。假设 someStep 步骤的结果数据如下:
{
"data": 002,
"other": "xxx"
}
那么该步骤实际执行中就会查询一篇 ID 是 002 的文章。
另外,API参数 和 前序步骤 两个来源都能用 Json选择器 去选择实际值。在后面的 值 文本框中输入以 $ 开头的表达式,就可以用表达式语法选择 JSON 数据的值。
假设某个值来源的数据格式如下:
{
"data": 002,
"other": [
{
"a1": 1
},
{
"a1": 2
}
]
}
此时在 值 文本框中填写 $.other[1].a1 就会在实际执行中得到 2 。你可以在此处 Demo中实际测试。
同理,Token数据 来自于用户 token 解析后的数据对象。
固定设置 则是直接用此处填写的 值:
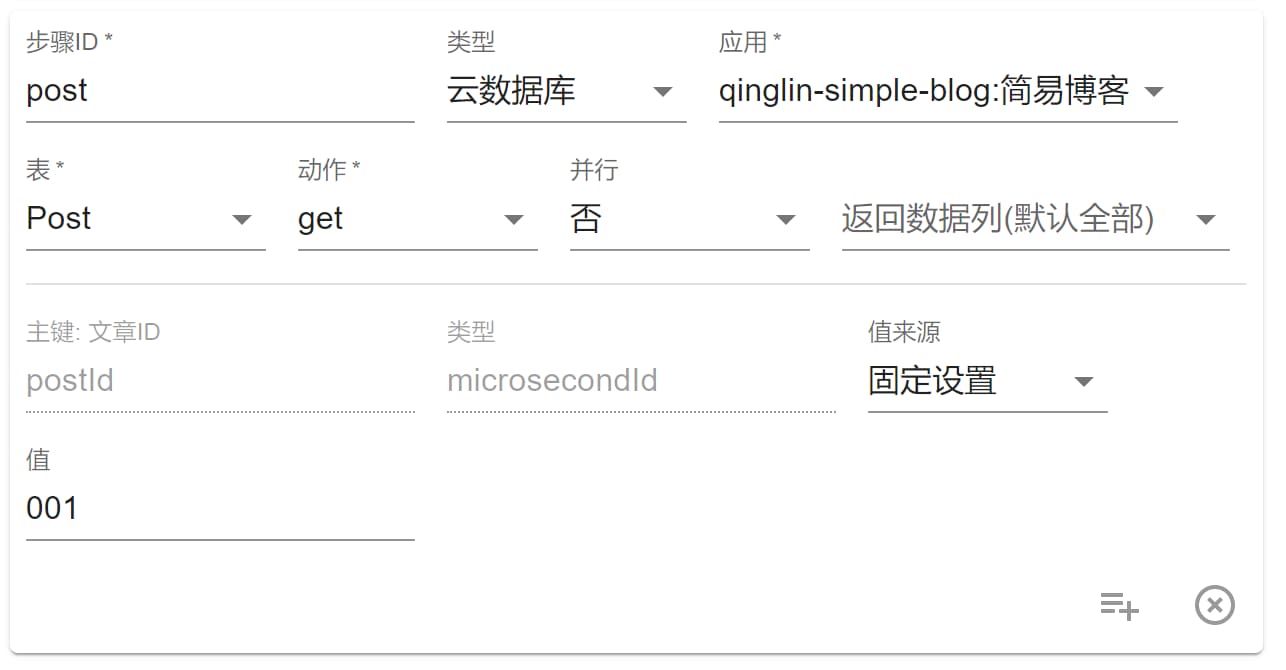
表示该步骤实际执行中就会查询一篇 ID 是 001 的文章。
随机id 则会生成一个随机值,会默认生成 21 个字符组成的值,例如:yorhcDIFv2V-KyKE5YRa6。
而在后面的 值 文本框中填写数字 10 时,这个随机值会生成 10 个字符组成的值如yorhcDIFv2。值 决定了随机值的长度。
时间戳 是该步骤实际执行时的 linux 时间戳,格式为 1622800165883 ,如果在后面的 值 文本框中输入 1000 或 -1000 则会将执行时的时间戳加 1 秒或减 1 秒,以此类推。
时间戳随机值 是 linux 时间戳加上 10 位随机值,格式为 1622800165883yorhcDIFv2 ,适用于按时间设置的 ID 并且严格要求唯一性的数据。
唯一微秒 是 A 系列引擎执行数据库 create 动作时才会用到的,意思是自动生成微秒 ID。
另外还有数据库 getMany 动作下才有的两个选项:无限大和无限小即 getMany 的范围,当后面的 值 文本框中有设置时,将优先采用 值来源 为 API参数 的效果,没有该 API 参数时会回退到无限数。
云数据库
该步骤的很多名词和功能解释在云数据库章节,需要提前阅读。
首先是最核心的 云数据库 类型,当我们选择步骤类型为 云数据库 后,会显示类似如下界面:
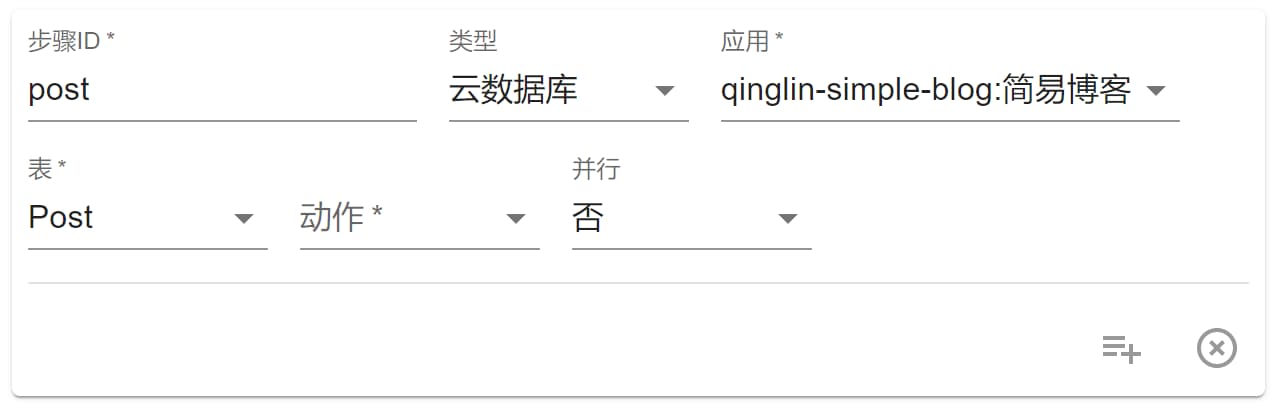
要求继续选择应用、表、动作和是否并行。
应用 可以选择当前组织所有已安装的应用,表 可以选择前步选择应用的所有数据表。
发现了没有,得益于该设计的灵活性,开发者可以将多个应用结合起来,或是对别的应用进行补充开发。
比如“用户系统”原应用没有提供根据昵称搜索用户的 API,但是我们完全可以做一个补充应用,设计对“用户系统”的 User 表进行昵称搜索的 API。这样所有应用都互通了。当用户安装你的应用同时也会安装所有你在 API 中调用了的所有其他应用。
积木式的应用开发使得我们能够通过多个应用的组合轻松完成一个大型的复杂应用,同时还保持足够的灵活性。
通用部分
返回值
在 get getMany search 中,有一个共同的选项为返回数据列,可以勾选本查询需要返回的数据列。因为有些时候不需要查全部的数据,全选可能会包括到一些不希望返回给前端的数据,比如隐私数据会泄露用户隐私,长文本数据会影响查询速度等。默认是全部返回。
选择列
在 create update 中,有一个共同的选项为选择数据列,可以选择在本步骤中新建或更新该条数据时需要用到的部分列。因为有时候单个 API 并不需要涉及到全部数据列的变更,所以选择后会更简洁。
另外,不管是选择了部分列还是全部列,只会变更有值的列,比如说 logo 的值来源是 API 参数,但是某个请求的 API 参数中没有 logo或者为空字符串,那么并不会更新该项,也不会将原先在数据库已经有的logo值变为空。
条件
在 create update delete 中,有一个共同的选项为条件,可以选择在本步骤中执行数据库动作时的提前检查条件。
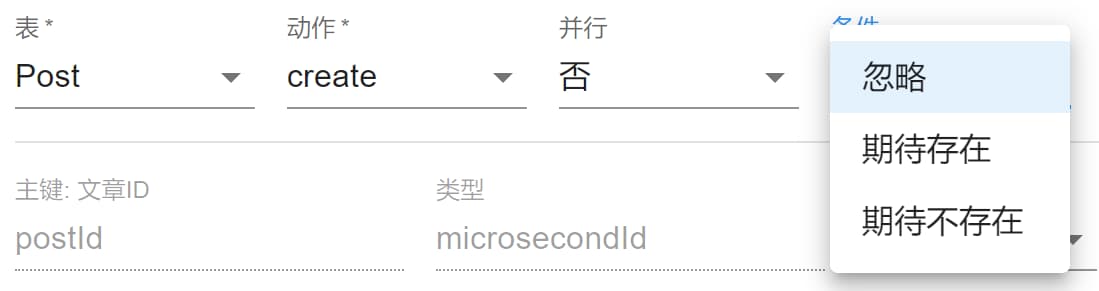
条件有三个:
忽略: 不管该主键值的数据是否存在,都会执行。如果有原数据,那么create会覆盖原数据,如果没有原数据,那么update会新建数据。期待存在: 期待符合该主键值的数据存在,如果没有该数据,那么都会报错Condition check failed。通常用于更新和删除希望已存在的值。期待不存在: 期待符合该主键值的数据不存在,如果该数据存在,那么都会报错Condition check failed。通常用于新建数据时防止覆盖已有数据。注意,主键值来源为随机id和唯一微秒时不要选择该项。
另外在 getMany update delete 中,有一个共同的按钮为添加条件,作用和上面类似也是前置检查,但是该条件是检查列数据的。
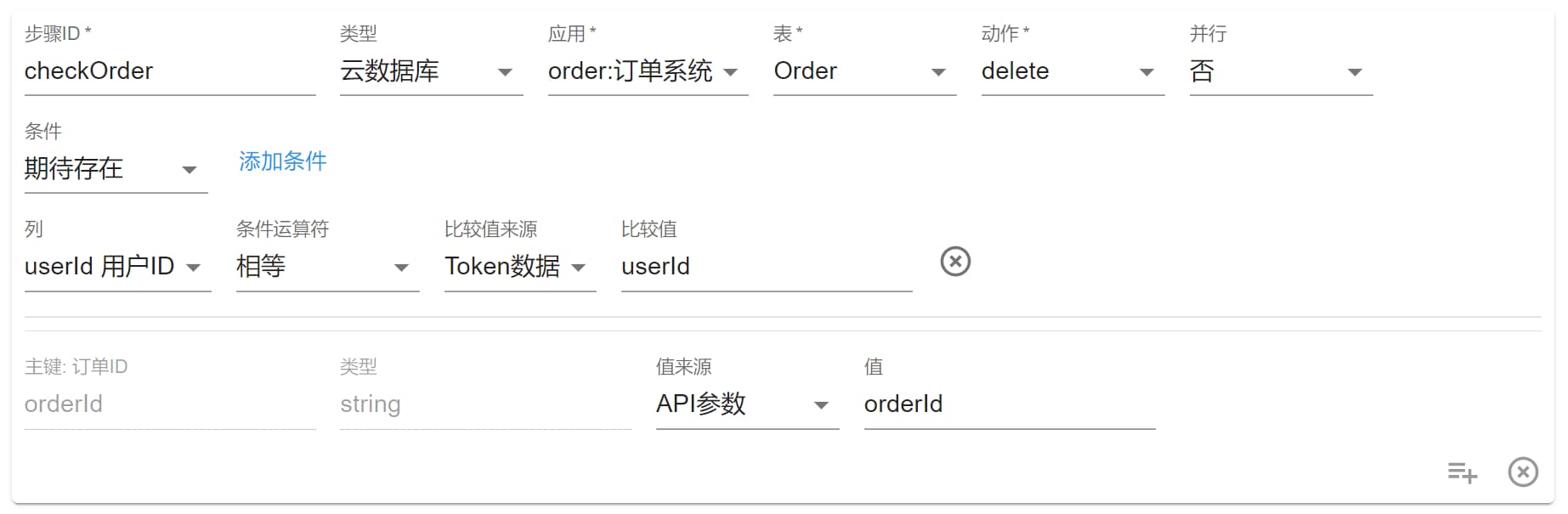
比如此处是一个删除订单的步骤,该订单只能被该订单的拥有者删除,而不能被别人删除,这里我们就可以添加条件,要求订单的userId和请求的 token 中的userId必须相等才能执行成功。
条件更新类似于乐观锁功能,即在更新某行数据时,先获取某列的值,假设为列 A,值为 1,然后设置条件列 A = 1,更新行使列 A = 2。如果更新失败,表示有其他请求已成功更新该行。
一个步骤同时最多 8 个条件。
非 NOT只生效第一个条件。
接下来我们要选择动作。
动作 有以下几种:
- get 查询单条数据
- getMany 查询多条数据
- create 新增数据
- update 修改数据
- delete 删除数据
- search 搜索数据(仅 S 系列引擎)
简单易懂,就是所谓的数据库增删改查。
并行 则是根据某个数组并行执行上述 动作。
我们继续拿“简易博客”应用中的 Post 文章表来举例。
get
选择 get 后如图所示:
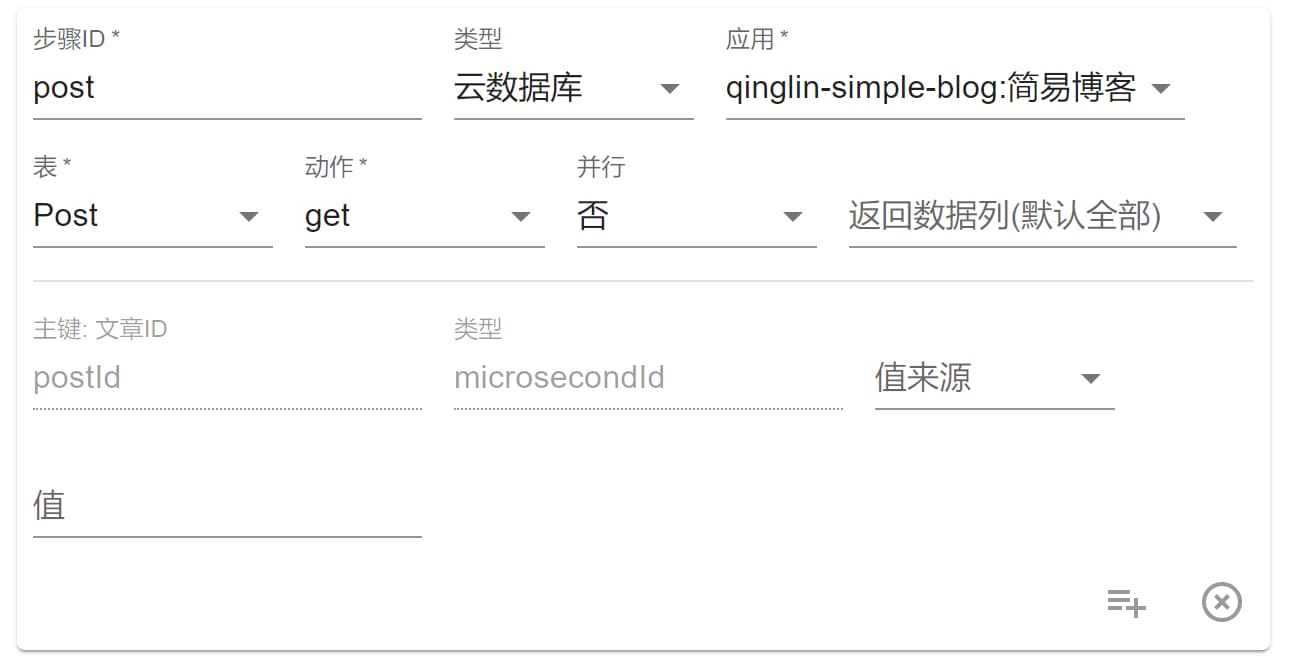
下方为主键区域,为主键选择 值来源 并设置 值 后就可查询该参数的数据。
步骤返回格式:
{
"步骤id": {
"id1": "a",
"id2": "b",
"data1": "c",
"data2": "d"
}
}
getMany
选择 getMany,此处我们用双主键的表“组织分组”作为示例,如图所示:
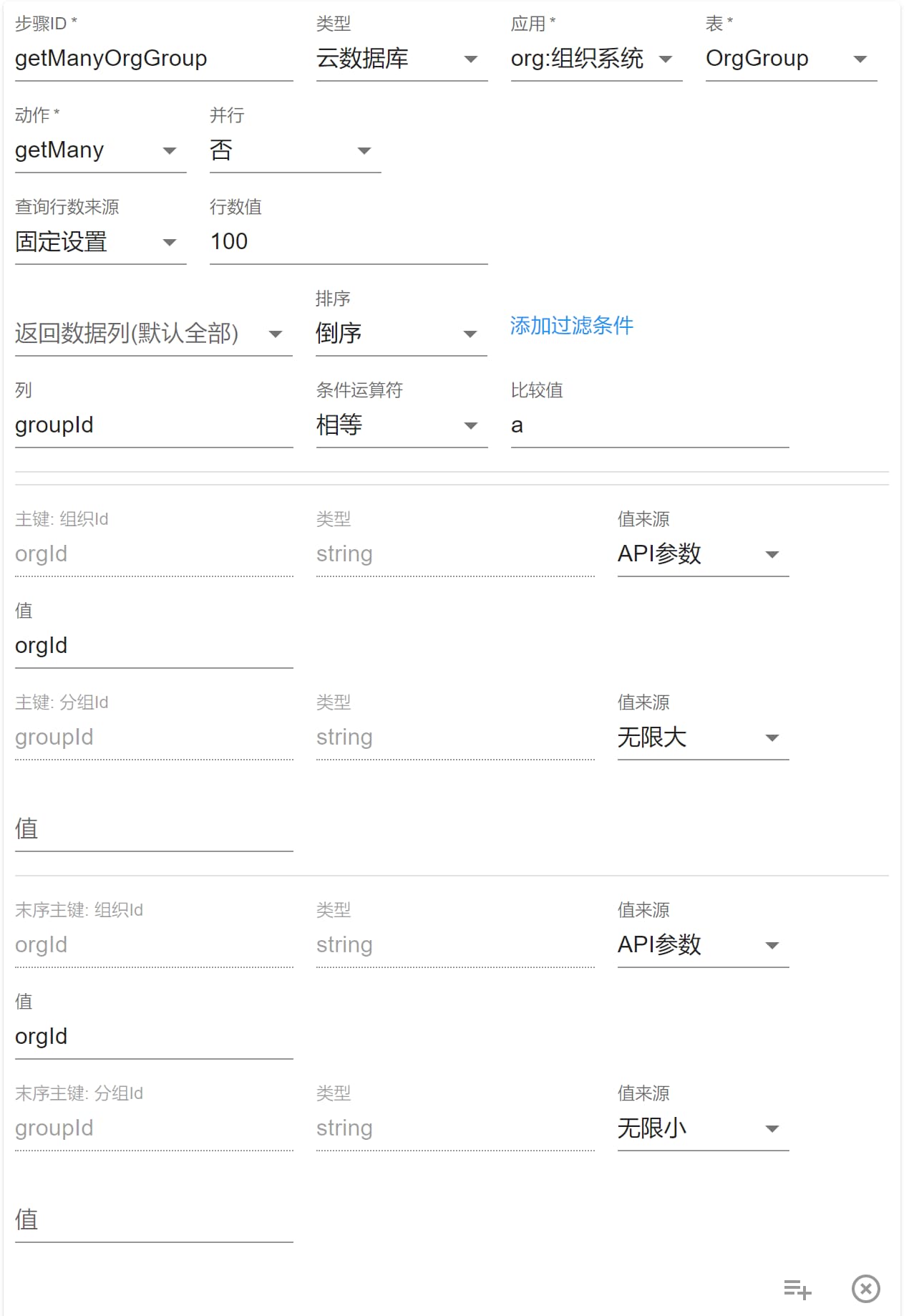
这时候会看到和前面的 get 不同,出现了两个主键区域。
首先我们要理解,getMany 是查询多条数据,那么肯定是要给定一个查询范围的,所以第一个主键区域确定查询的开始位置,第二个主键区域(会标注:末序主键)确定查询结束的位置。默认是按照字符表排序。
可以选择排序方式,正序就是 1 < 2 或 a < z这样,倒序就是反过来 2 > 1 主键大的排前面。
比如说有如下一些“组织分组”数据:
[
{
"orgId": "qinglincloud",
"groupId": "a"
},
{
"orgId": "qinglincloud",
"groupId": "b"
},
{
"orgId": "other",
"groupId": "a"
}
]
开始排列组合查询方式示例:
- 设置查询起始主键的值为
orgId = 无限大 , groupId = 无限大,结束主键的值为orgId = 无限小 , groupId = 无限小,排序为倒序,因为字符表顺序为o < q & a < b那么获得下列顺序:
[
{
"orgId": "qinglincloud",
"groupId": "b"
},
{
"orgId": "qinglincloud",
"groupId": "a"
},
{
"orgId": "other",
"groupId": "a"
}
]
- 设置查询起始主键的值为
orgId = 无限小 , groupId = 无限小,结束主键的值为orgId = 无限大 , groupId = 无限大,排序为正序,因为字符表顺序为o < q & a < b那么获得下列顺序:
[
{
"orgId": "other",
"groupId": "a"
},
{
"orgId": "qinglincloud",
"groupId": "a"
},
{
"orgId": "qinglincloud",
"groupId": "b"
}
]
如果指定前面的主键,那么只会查询指定范围:
- 设置查询起始主键的值为
orgId = qinglincloud , groupId = 无限大,结束主键的值为orgId = qinglincloud , groupId = 无限小,排序为倒序,因为字符表顺序为a < b那么获得下列顺序:
[
{
"orgId": "qinglincloud",
"groupId": "b"
},
{
"orgId": "qinglincloud",
"groupId": "a"
}
]
然后给范围设定值:
- 设置查询起始主键的值为
orgId = qinglincloud , groupId = b,结束主键的值为orgId = qinglincloud , groupId = a,排序为倒序,此时我们要注意,范围查询是左闭右开区间,也就是说,起始范围的值如存在则会包含,结束范围的值不管有没有都不包含。获得下列数据:
[
{
"orgId": "qinglincloud",
"groupId": "b"
}
]
另外要注意,选择排序为 倒序 时,起始值一定要比结束值大,选择排序为 正序 时,起始值一定要比结束值小。
范围查询默认查询 100 行,最大查询 4000 行或者 3 MB 大小的数据(整个 API 所有返回数据不得大于 5MB)。查询的数量由 查询行数来源 和 行数值 确定。你可以设置来源为 API 参数,行数值 为 postsLimit,这样查询行数就是 API 参数中的 postsLimit 项的值。
最后还有一个 添加过滤条件 功能:
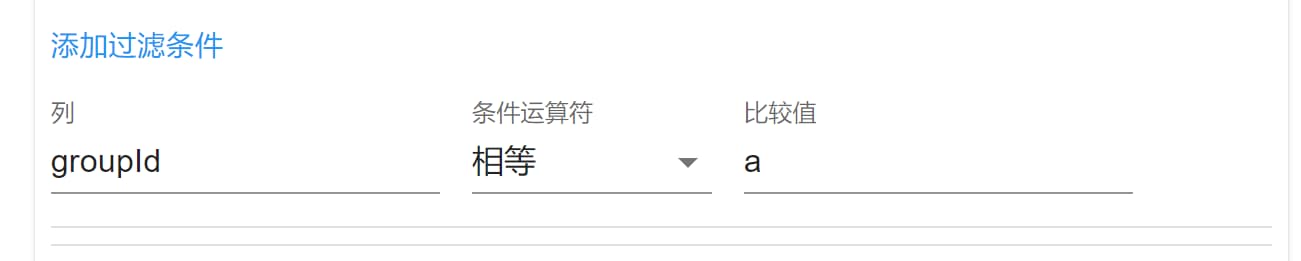
条件运算符有这些:
= != > < >= <=作用如同符号。
可以过滤查询结果,如上图所示,就会过滤掉 groupId 不等于 a 的数据。
可以有多个过滤条件。
注意过滤是在查询之后进行,即假如查询行数值设置为固定值 4000,就会先查 4000 行数据出来,然后过滤成 100 行,最后也只有 100 行返回,并不包含这 4000 行后面符合过滤条件的数据,如需查询更多,此时你可以使用返回的nextId再查询后面的数据。
C 系列引擎还会有
镜像表选项,具体请查看云数据库文档。
步骤返回格式:
{
"步骤id": {
"data": [
{
"id1": "a",
"id2": "b",
"data1": "c",
"data2": "d"
}
],
"nextId": {
"id1": "a2",
"id2": "b2"
} // 无则为 null
}
}
create
选择 create 后如图所示:
基本各部分作用前面已有介绍。
步骤返回格式:
{
"步骤id": {
"id1": "a",
"id2": "b"
}
}
update
选择 update 后如图所示:
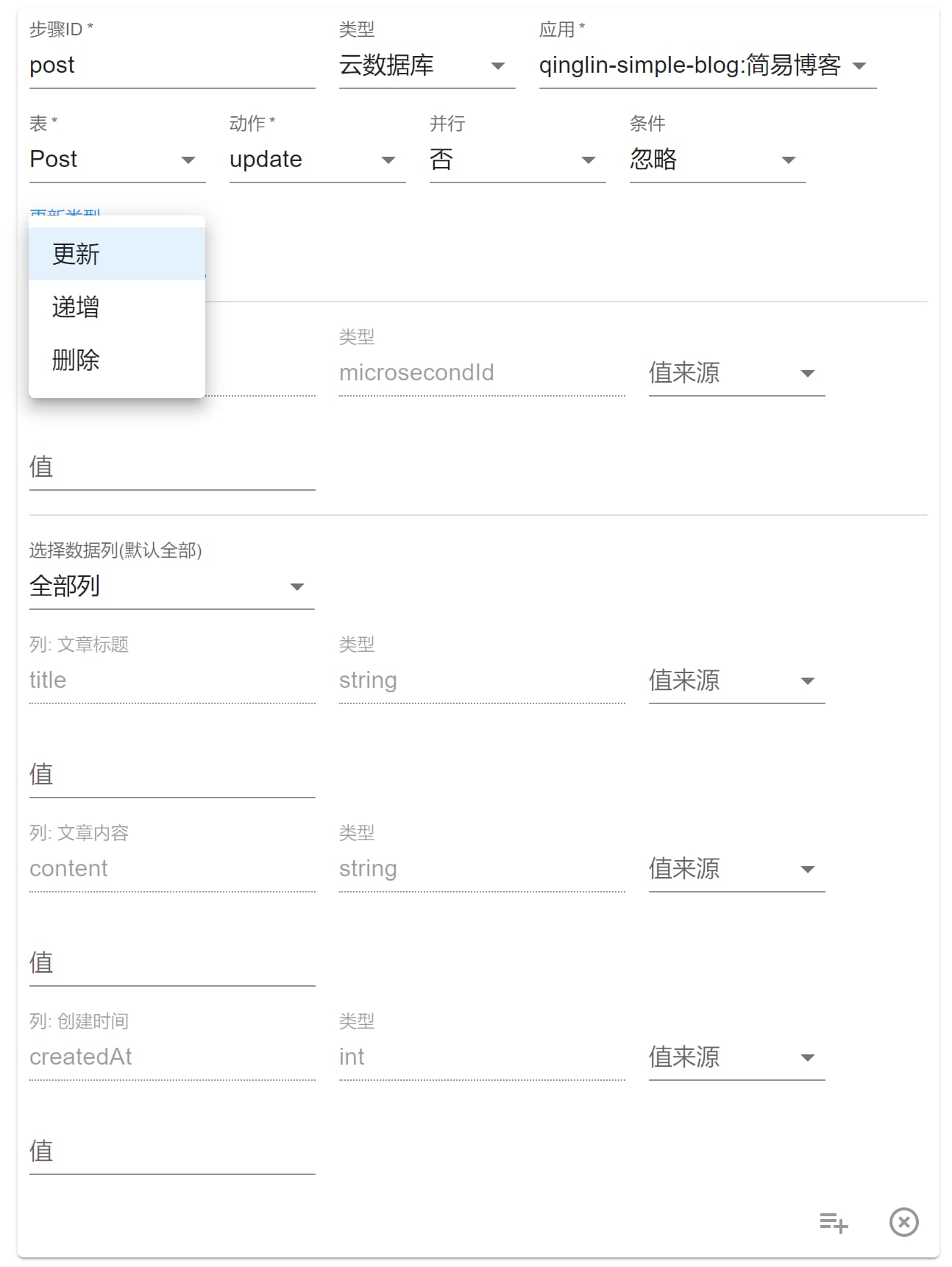
多了一个选项为 更新类型,有三种:
- 更新:基本和
create相同。 - 递增:只能选择
int类型的数据列,更新值同样为整数数字,将会原子式递增或递减。 - 删除:
选择数据列确定要删除的列数据,值来源和值都可以忽略。
注意此处 递增选项,非常有用。假设有一个比较常见的场景,帖子点赞:
在传统数据库中,常用的做法是先查询得到该条帖子的点赞数,然后加 1,再将更新数字写入进数据库。
但是如果该帖子很火,有很多人同时点赞,那么在分布式的情况下,多个服务同时查询帖子点赞数得到值为 10 , 加 1 后为 11,再同时写入数据库,结果多个点赞同时进行的情况下只会最终+1,甚至有个别服务比较慢,还会出现回退。所以不得不使用数据库事务,锁住数据库后查询、加 1 再更新后解锁。有非常严重的性能问题。
Redis 等数据库就做了个功能是原子递增,即不管同时有多少并发,不需要先查后更新,直接给数据库一个递增值,数据库层面就完成了数字更新。分布式服务只需要发送递增值就行了,返回给它递增后的数据。完美解决上面的问题。
此处的递增就是这样的实现。递增值可以为正整数也可以为负整数。
步骤返回格式:
{
"步骤id": {
"id1": "a" // 如果是递增类型则返回的是递增项
}
}
delete
选择 delete 后如图所示:
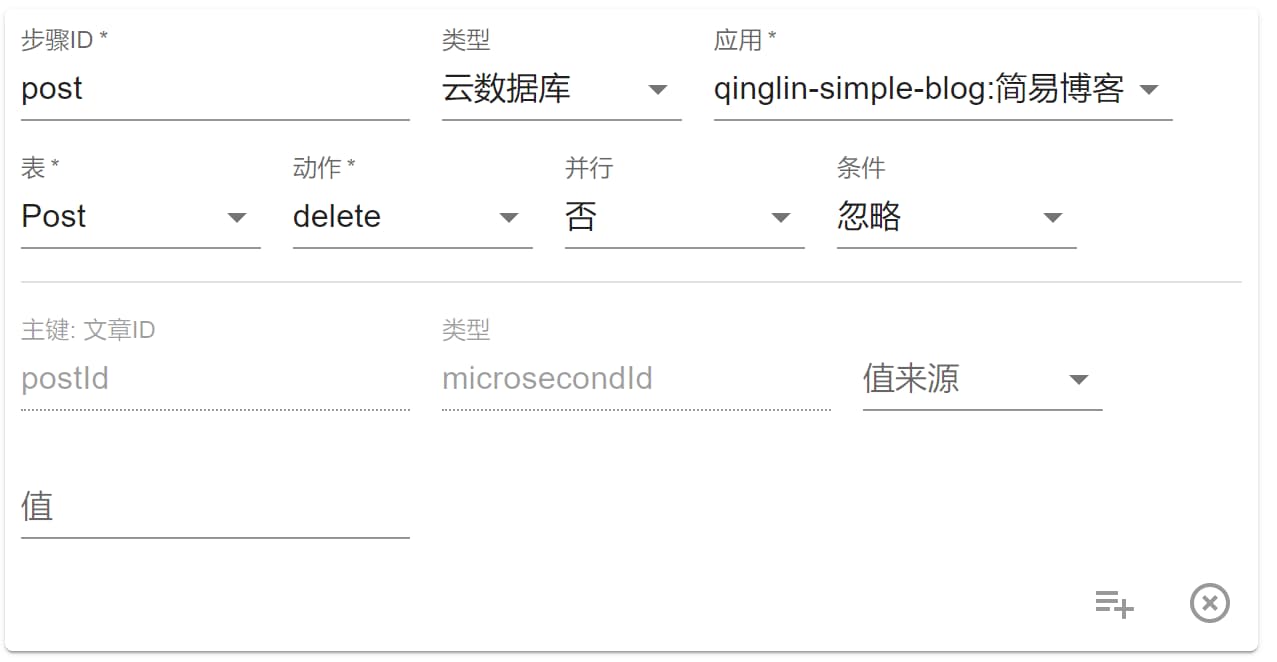
基本和 get 一样。
步骤返回格式:
{
"步骤id": {
"success": true
}
}
search
search 选项只在当前表为 S 引擎时出现,此处我们就用“用户系统”的User表做例子:
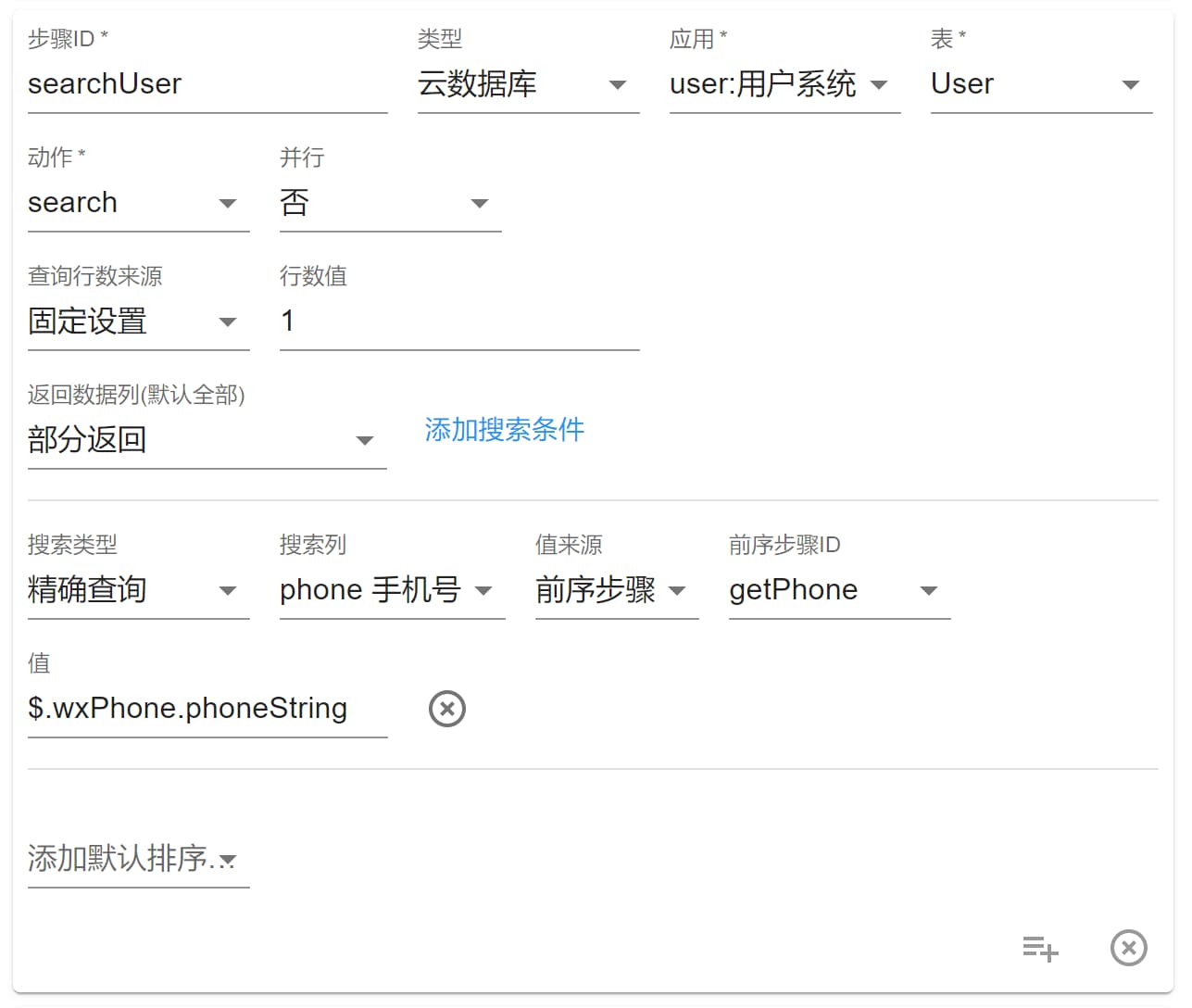
search 的查询没有主键区域,因为主键和所有的列都可以查询,主要由搜索条件控制,添加多个搜索条件就会查询到符合多个条件的数据。
上面的例子是根据手机号查询用户,所以类型是精确查询。所有类型如下:

- 精确查询要求查询值和数据值完全相等。
- 匹配查询一般应用于全文检索场景,可应用于 text 类型。查询值能匹配到数据值其中一部分即可,数据值是分开的也可以。
- 短语匹配查询类似匹配查询,但查询值要完全匹配数据值的一部分。
- 范围查询类似 getMany,只不过原先的主键范围也可以用于列范围。
- 前缀查询即查询值满足数据值的前缀即可。
- 相关性查询会计算查询值和数据值的相关性。
- 因子相关性则会额外加入一个因子参数来计算相关性。
- 嵌套查询则是查询 nested 类型数据。
- 通配符查询可以有
*代指任意字符,?代指单个字符去查询数据。 - 总行数查询,只查符合条件的行数。
- 地理长方形查询类似地图 APP,在一个长方形内查询相关数据。
- 地理距离查询是在查询经纬点距离内的经纬数据。
- 地理多边形就是将上面的长方形改为多边形。
- 多词精确查询是精确查询的数组形式。
- 列存在查询常用于确认某个列是否存在数据。
当然,在查询多条数据时,可以由前端控制排序类型,可以多个组合。

主键排序和getMany一致。
列排序也类似,只不过比较值成了数据列。
相关性查询适用于全文检索场景,使用了 BM25 算法计算相关性。
地理点排序适用于位置排序,比如“附近的人”这种场景。
具体请查看 API 格式 文档。
步骤返回格式:
{
"步骤id": {
"data": [
{
"data1": "c",
"data2": "d"
}
],
"nextToken": "xxx" // 用于翻页查询,无则为 null
}
}
并行
并行 选项意思是是否并行执行该步骤,并行需要一个数组来提供并行执行的数量和并行参数,我们以“组织系统”中的getManyUserOrgAPI 为例:
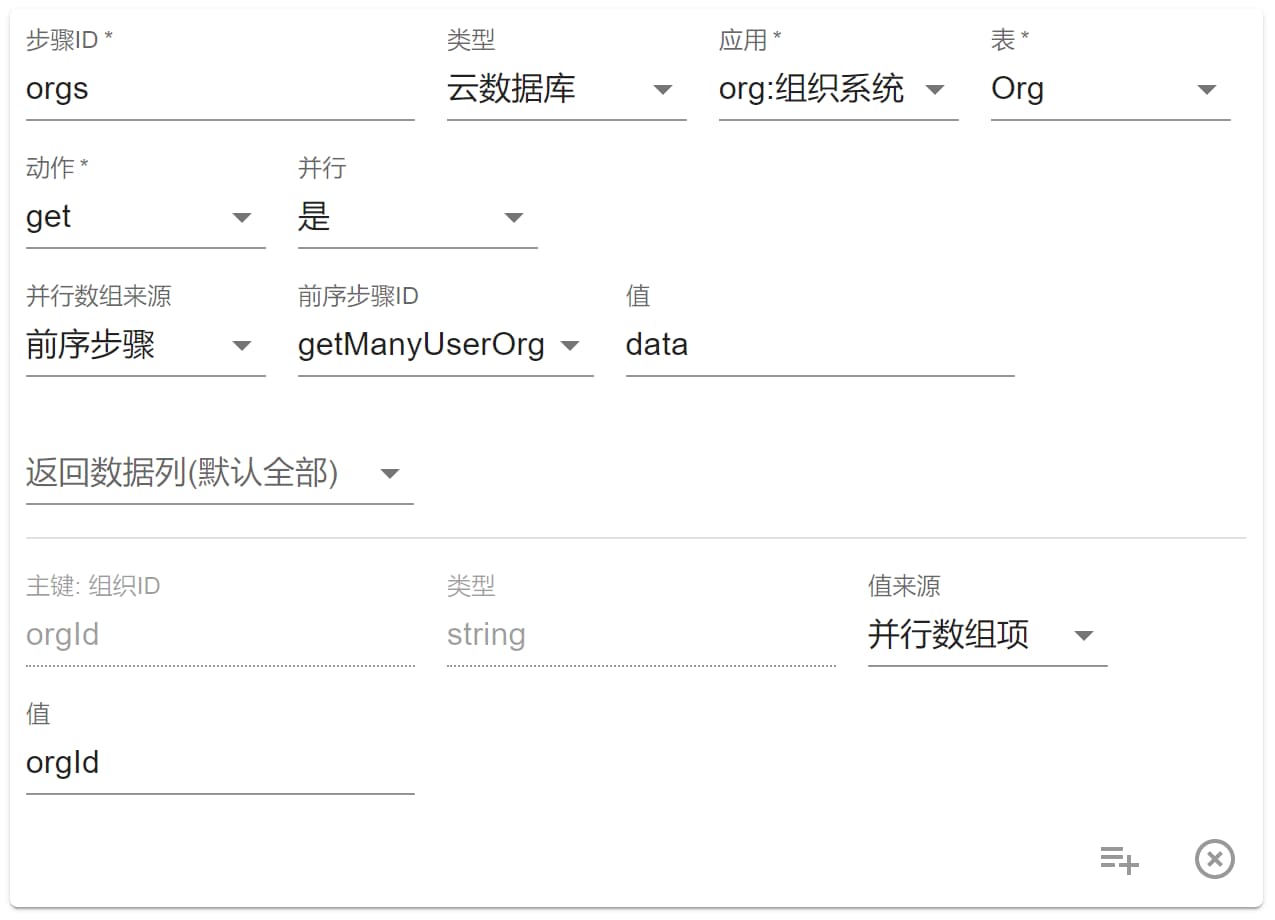
这个步骤的前一个步骤 getManyUserOrg 查询到了所有该用户加入了的组织的信息,但因为这是一个中间表,没有组织的具体数据,只储存了 orgId,那么我们就需要一个并行步骤来查询所有的相关组织。
这里数组来源于上个步骤的data数组,然后下方get动作中多了个值来源 并行数组项,可以选择该值获取到本次并行执行时的值。
用前端代码来描述如下:
const list = [1, 2, 3]; // 并行数组
list.map((item) => {
// 此处 item 就是并行数组项
getData(item); // 并行执行步骤
});
步骤返回格式:
{
"步骤id": [
{
"id1": "a",
"id2": "b",
"data1": "c",
"data2": "d"
},
{
"id1": "a2",
"id2": "b2",
"data1": "c2",
"data2": "d2"
}
]
}
条件判断
条件判断类似于 if 逻辑。
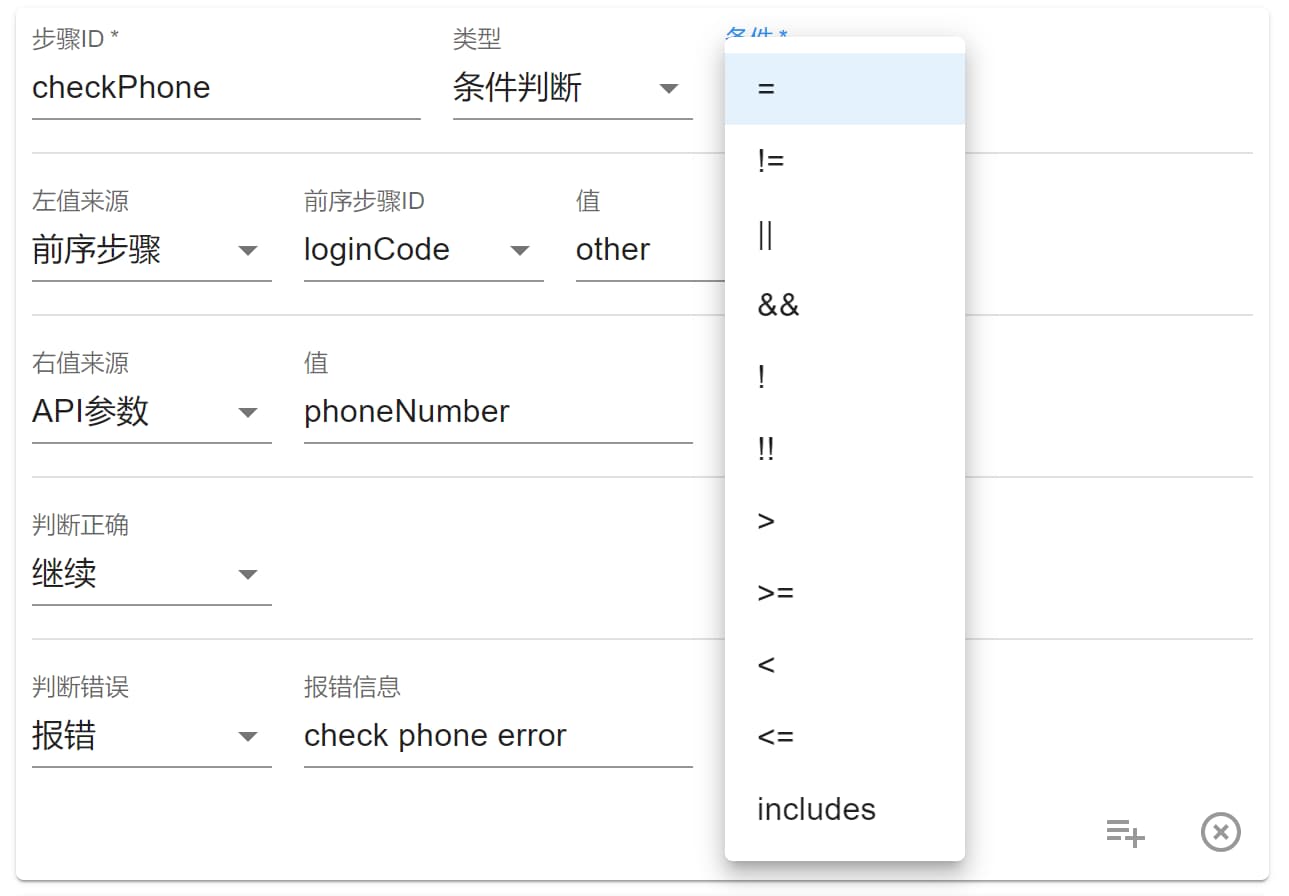
可以对左值和右值进行判断,符号的话有前端基础应该都懂,只不过 = 和 != 是 js 中的=== 和 !==。
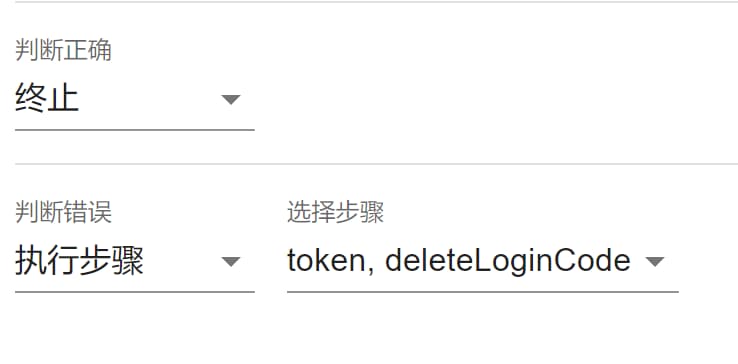
得到判断结果后即可根据结果有不同的行为。
继续则会继续执行下面的步骤。报错则会返回报错信息。终止则会终止所有步骤并返回前面和当前的步骤数据。执行步骤则会执行被选择的步骤,跳过没有被选择的步骤。
步骤返回格式:
{
"步骤id": true // or false
}
JS 脚本
在某些场景,我们需要处理一些特殊的值,但是又不能放到前端处理,那么 JS 脚本 步骤就派上用场了。
该步骤可以用 JavaScript 语言执行一些运算。
JS 脚本 有两种环境:JS 环境 和 Node 环境,第一种类似于在浏览器开发者工具 Console 中的体验,第二种是类似 Nodejs 环境中的体验。
直接举例,在“用户系统”中,有个 API 是创建手机短信验证码,这个逻辑很简单,但是我们不能在前端创建,不然就可能会被非法用户截取到,所以这里我们用该步骤如下:
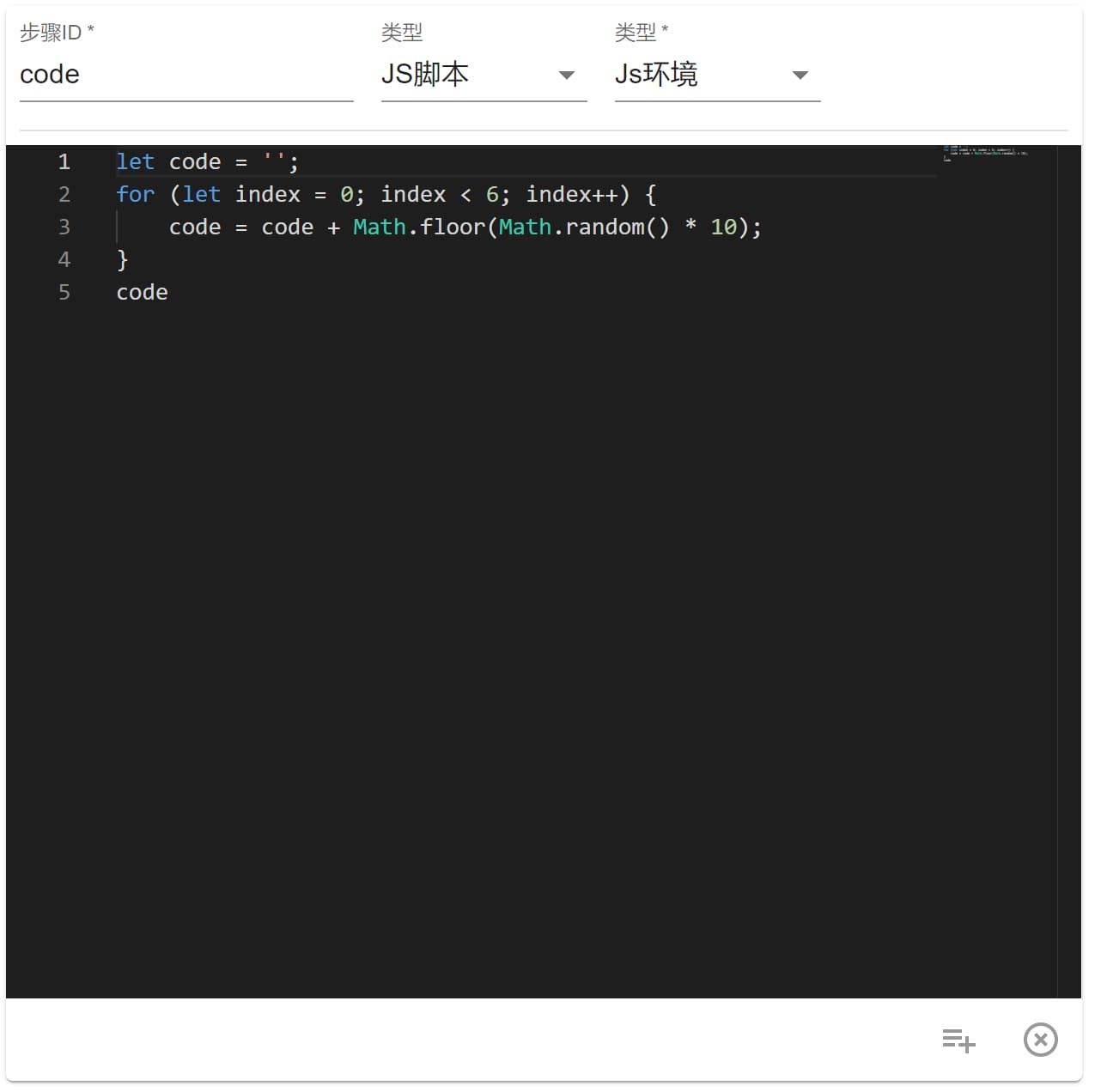
因为逻辑非常简单,这里就用了第一种JS 环境,该步骤的值就是 code 这个随机数。
那么第二种 Node 环境 就比较适合复杂的计算或者需要 nodejs 库的步骤,比如同样在“微信常用接口”应用中有个 API 是从微信加密数据中解析手机号的,用到了加密库crypto,也比较复杂,那么如下所示:
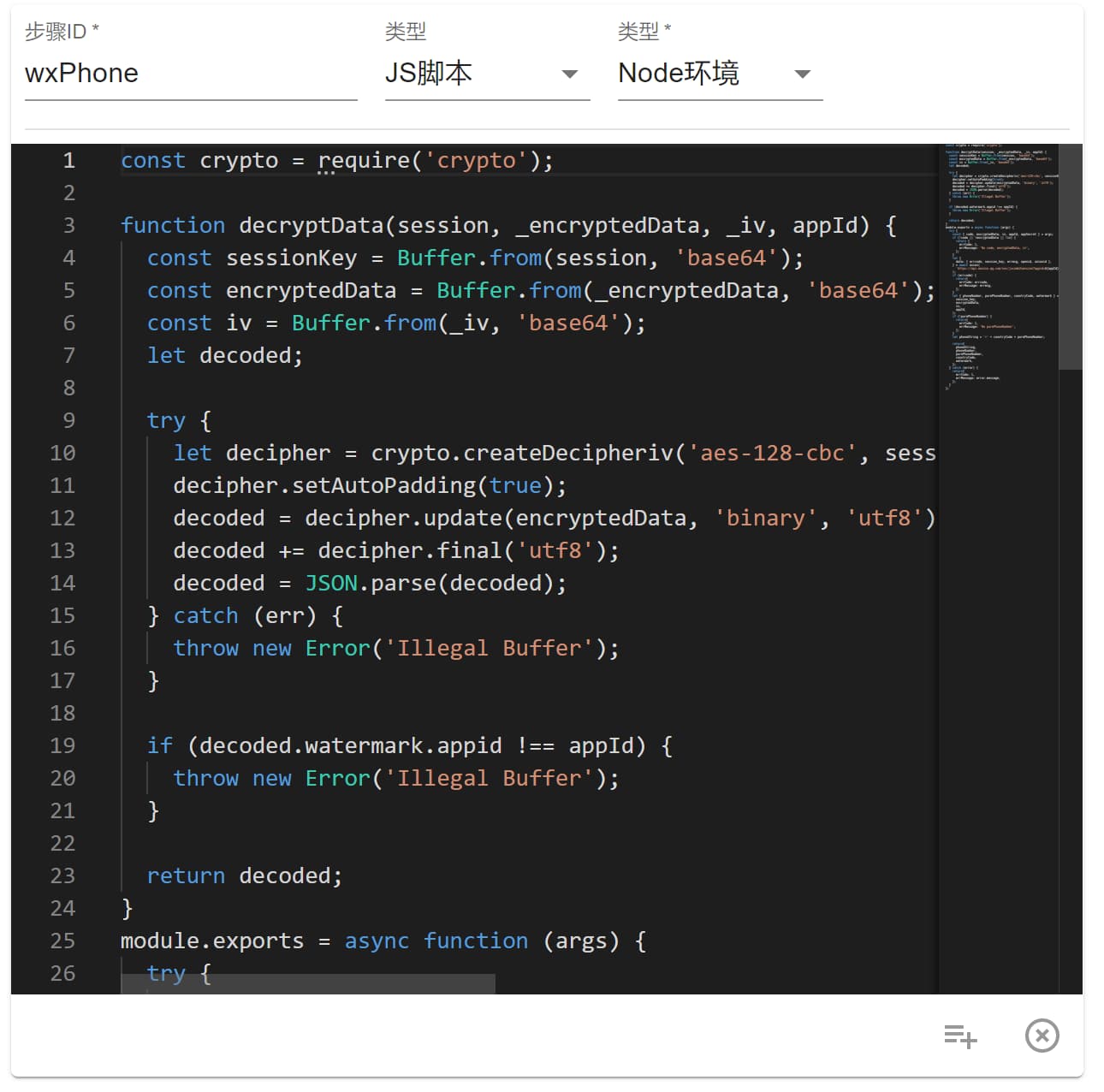
完整代码在这里:
const crypto = require("crypto");
function decryptData(session, _encryptedData, _iv, appId) {
const sessionKey = Buffer.from(session, "base64");
const encryptedData = Buffer.from(_encryptedData, "base64");
const iv = Buffer.from(_iv, "base64");
let decoded;
try {
let decipher = crypto.createDecipheriv("aes-128-cbc", sessionKey, iv);
decipher.setAutoPadding(true);
decoded = decipher.update(encryptedData, "binary", "utf8");
decoded += decipher.final("utf8");
decoded = JSON.parse(decoded);
} catch (err) {
throw new Error("Illegal Buffer");
}
if (decoded.watermark.appid !== appId) {
throw new Error("Illegal Buffer");
}
return decoded;
}
module.exports = async function (args) {
try {
const { code, encryptedData, iv, appId, appSecret } = args;
if (!code || !encryptedData || !iv) {
return {
errCode: 1,
errMessage: "No code, encryptedData, iv",
};
}
let {
data: { errcode, session_key, errmsg, openid, unionid },
} = await axios(
`https://api.weixin.qq.com/sns/jscode2session?appid=${appId}&secret=${appSecret}&js_code=${code}&grant_type=authorization_code`
);
if (errcode) {
return {
errCode: errcode,
errMessage: errmsg,
};
}
let { phoneNumber, purePhoneNumber, countryCode, watermark } = decryptData(
session_key,
encryptedData,
iv,
appId
);
if (!purePhoneNumber) {
return {
errCode: 1,
errMessage: "No purePhoneNumber",
};
}
let phoneString = "+" + countryCode + purePhoneNumber;
return {
phoneString,
phoneNumber,
purePhoneNumber,
countryCode,
watermark,
};
} catch (error) {
return {
errCode: 1,
errMessage: error.message,
};
}
};
函数需要module.exports出来,并且可以在函数入参中拿到 API 参数。
在Node 环境 中,可以使用的内置库有:
- crypto
- querystring
- tls
- util
- zlib
如果你的应用需要额外库,可以联系客服。
另外还有全局变量:
- tokenData 用户 token 解析后的数据
- steps 即前面步骤的数据
步骤返回格式:
{
"步骤id": "格式取决于脚本"
}
其他 API
其他 API 可以调用其他 API,甚至可以跨应用。
这一特性非常实用,在应用市场中有很多通用型应用,我们可以直接拿来使用,就不用再费力开发了。
同时在大型应用中也比较常见,我们通常将大应用拆分成不同模块应用,然后组合起来提供完整服务。
比如上面的步骤,“微信常用接口”应用有个比较复杂的解析手机号接口,在“用户系统”中我们需要用户小程序手机号登录,那么就调用那个接口:

可以看到这里传值进去。然后那边的参数会收到这边传的值。两个步骤相互参考理解。
注意,被调用的其他 API 中的其他API步骤将不会被执行,不然就可能出现死循环了。
再注意,调用其他 API 时默认有所有权限,其他 API 的前置权限约束将无效,但是流程中的权限相关步骤依然有效。
步骤返回格式:
{
"步骤id": "其他API 的返回格式"
}
HTTP 请求
HTTP 请求 步骤可以发送网络请求。
在某些功能中,我们需要去调用第三方的接口,那么就可以使用该步骤,比如下面所示,我们需要调用微信的接口,获得 access token 和 小程序码:
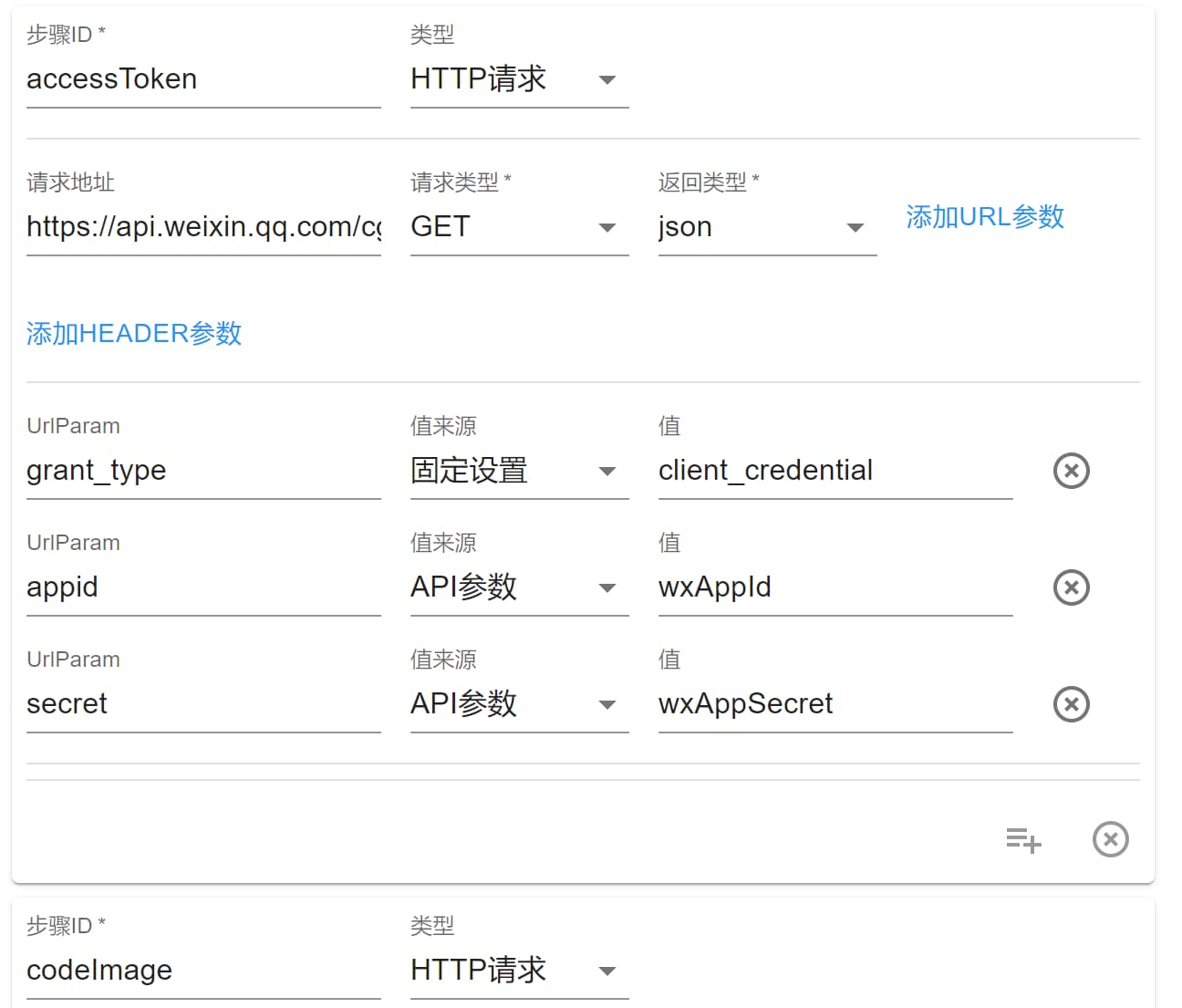
得到 access token 后我们就可以再调用接口获取小程序码了:
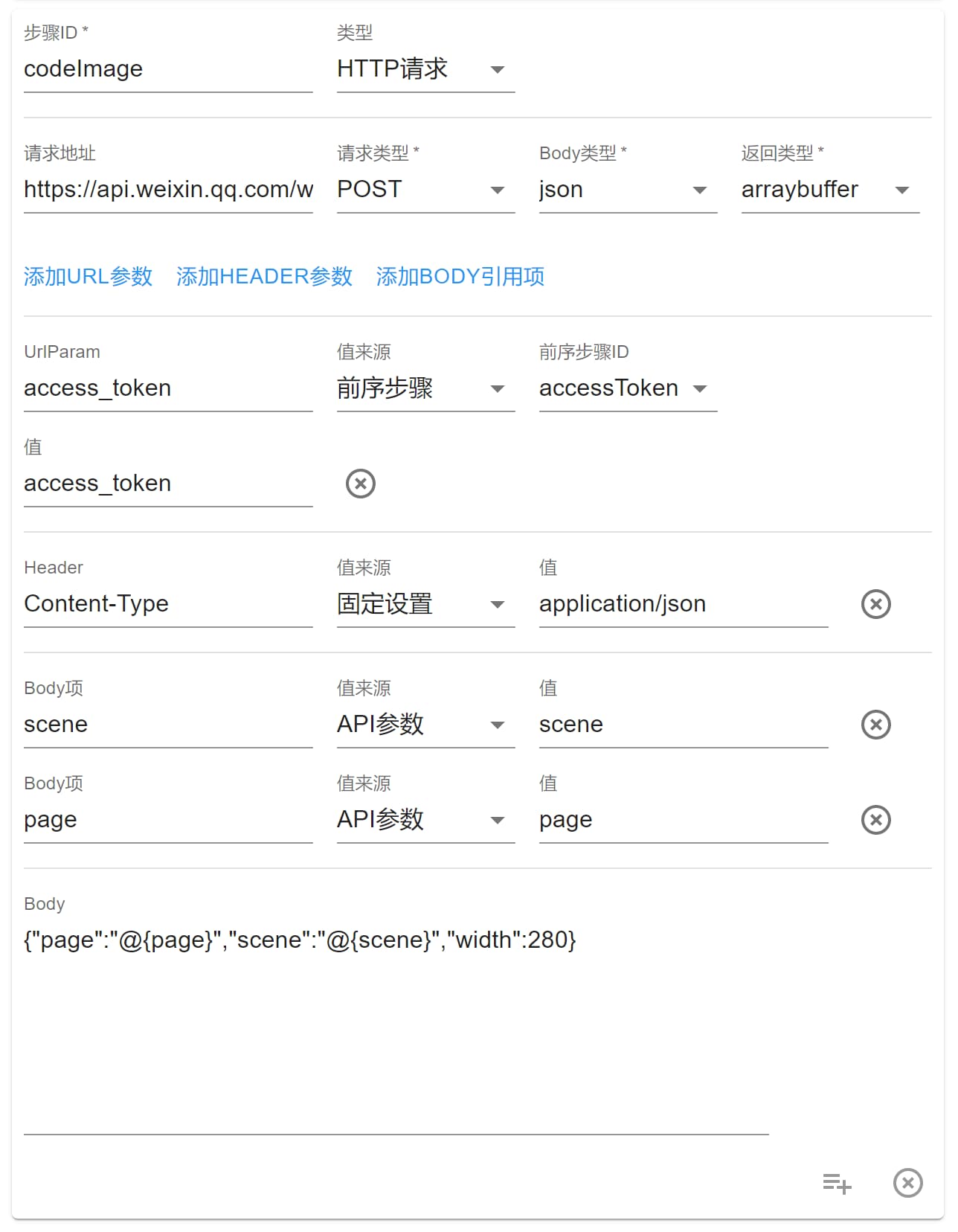
这两个步骤加起来就是一个完整的 API。这里的 Url search 参数、headers 参数、body 参数都能设置,需要注意的一点就是 Body 中是 String 字符串格式,@{} 符号包含的区域可以被替换为上面的 Body项 的值。
步骤返回格式:
{
"步骤id": "HTTP 请求的返回数据"
}
Json 选择
本步骤和 值来源 中的 $ 表达式相同,经常用来选择某些数据供后续步骤使用或返回。
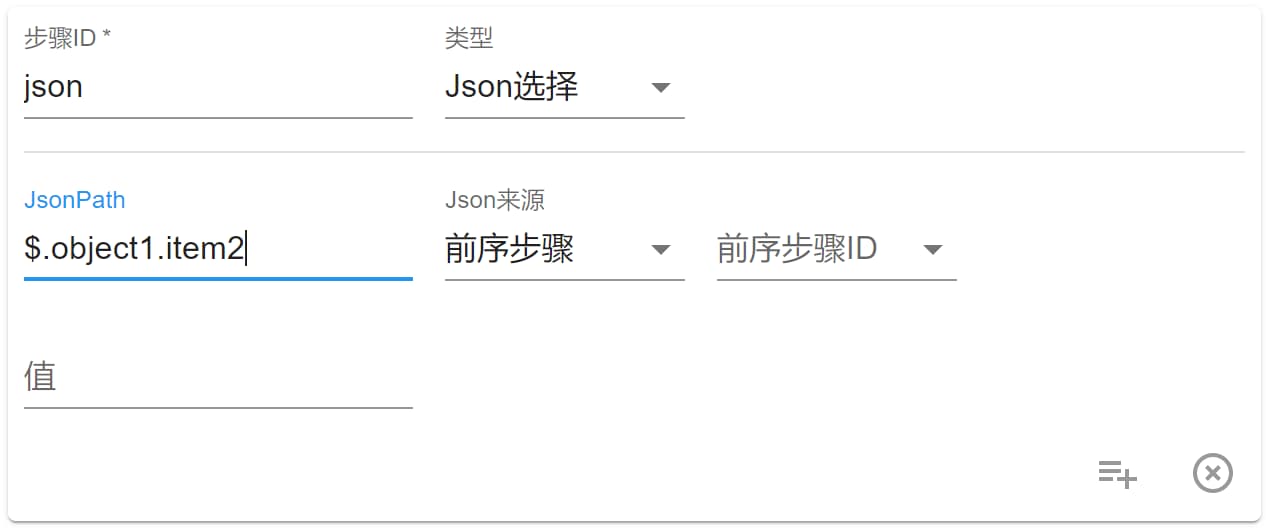
实验工具网址:https://jsonpath-plus.github.io/JSONPath/demo/
步骤返回格式:
{
"步骤id": "选择的 Json 项"
}
自定义函数
该步骤用于执行自定义函数。
如果你的应用逻辑需要用到一些特殊的库,或者其他语言,或者及其复杂,那么可以使用自定义函数,具体看这里:
步骤返回格式:
{
"步骤id": "格式取决于你的函数"
}
获取配置
能够获取应用使用者填写的应用配置项。
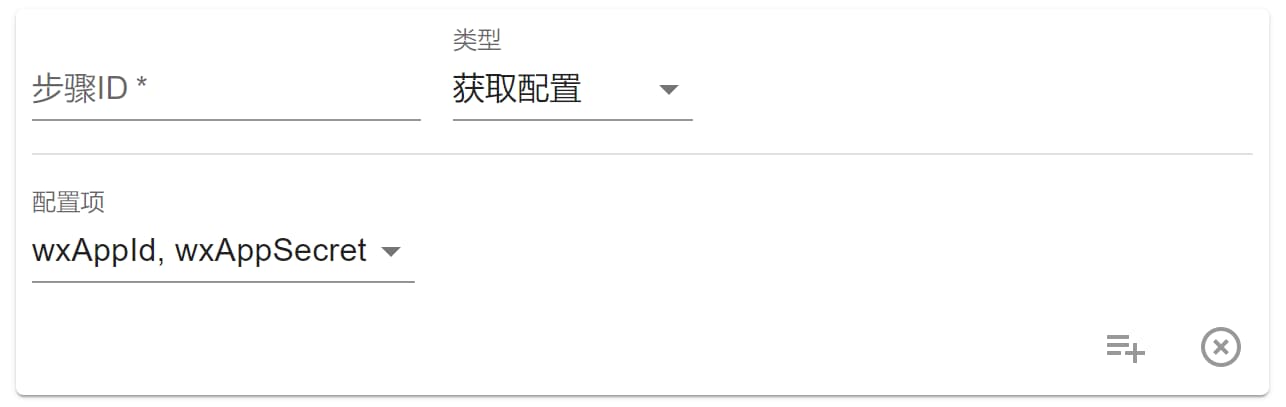
步骤返回格式:
{
"步骤id": ["配置1", "配置2"]
}
简单计算
简单计算步骤如其名,如下所示:
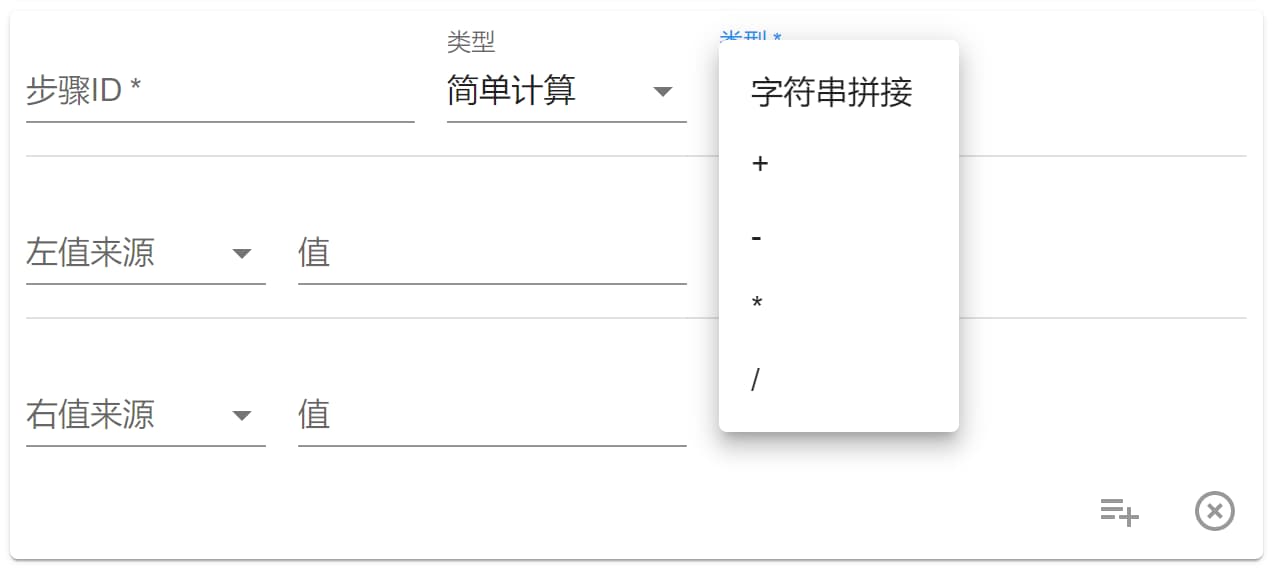
+ - * / 四则运算会将左值右值转换成 Int 类型再计算。字符串拼接 可以拼接两个字符串。
步骤返回格式:
{
"步骤id": 2 // 计算结果或 "拼接后的字符串"
}
Json 转换
就是类似于 JavaScript 中的 JSON.parse() 和 JSON.stringify()。
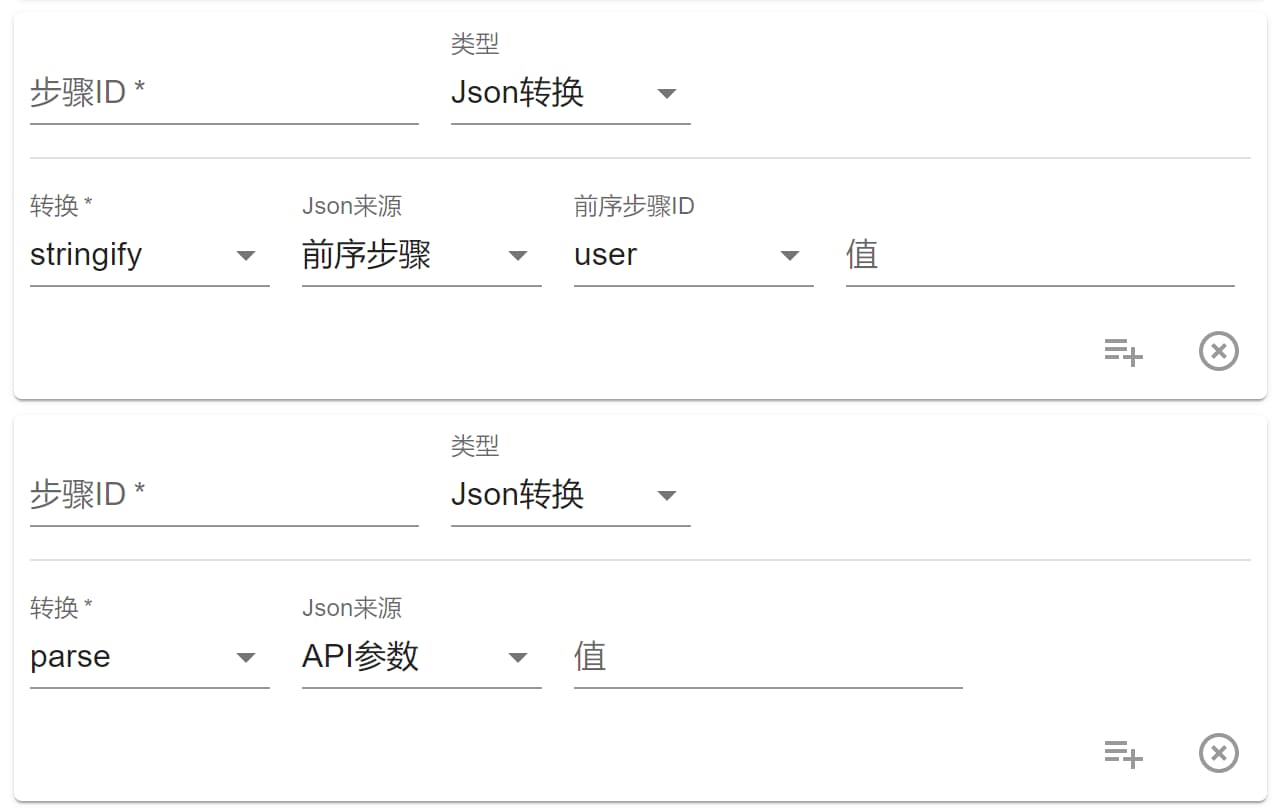
步骤返回格式:
{
"步骤id": "转换结果" // 或parse后的JSON对象
}
数组操作
两个数组的操作。(请尽量使用脚本步骤,本步骤在非熟悉情况下出错几率高)
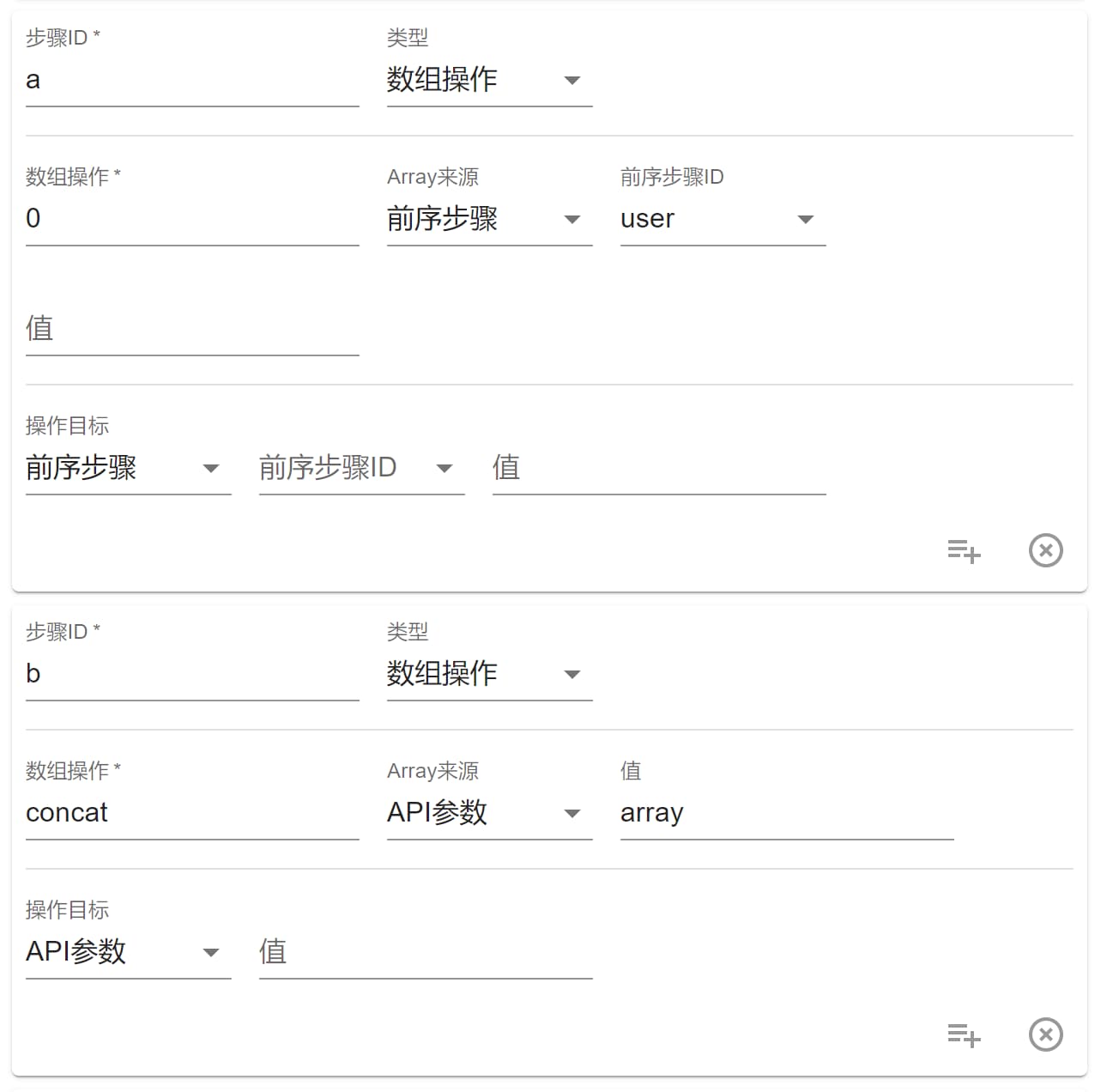
a 步骤中,当 数组操作 为数字时,可以进行数组选择,类似于["a","b"][0]。
b 步骤中,当 数组操作 为 concat 时,表现和 js 的数组 concat 一致。
步骤返回格式:
{
"步骤id": ["操作结果"] // or 选择项
}
JWT
该步骤可以使用环境密匙的密文对数据项进行签名:
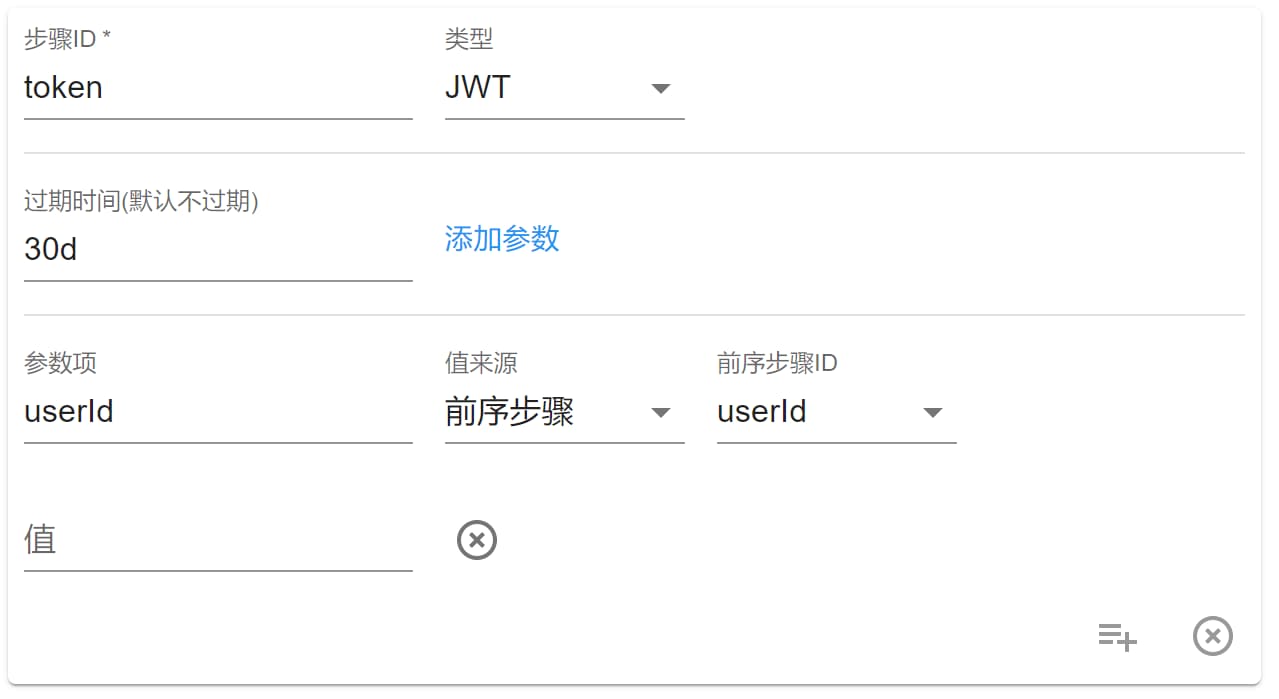
如图,就是对 userId 进行了签名。
过期时间格式为毫秒,但也可以用简写:
- y : 年
- d : 天
- h : 小时
- m : 分
- s : 秒
步骤返回格式:
{
"步骤id": "jwt token"
}
返回自定义数据
在某些情况下,第三方业务调用 BaaS API 时,需要有特定的返回格式,所以该步骤可以自定义设置返回格式。
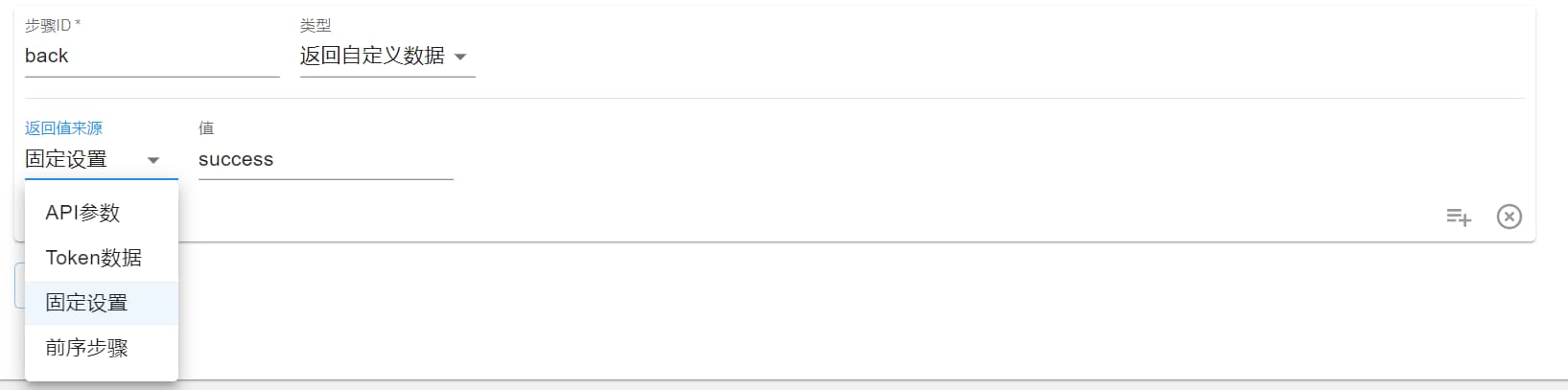
同样设置返回值来源和值去确定要返回哪些数据。原理同上。
注意:当在任意步骤中设置该步骤时,会立即返回自定义数据,不再继续执行步骤,同样的左侧设置的返回步骤也将不起作用。